
Ограничения: почему бывает сложно парсить
Многие задумываются о том, как защитить сайт от парсинга, потому что не хотят терять уникальность контента. Поэтому используют различные программы, которые запрещают доступ к ресурсу ботам.
Запреты могут накладываться на работу по следующим аспектам:
- По user-agent. Клиентское приложение отправляет запросы, чтобы получить информацию о пользователе. Многие вебсайты блокируют парсеры, но это можно избежать, если настроить все как YandexBot или Googlebot.
- По robots.txt. Здесь еще проще. Прописываем в настройках, что нужно игнорировать этот протокол.
- По IP. Подозрительно, что с одного адреса с удивительной регулярностью поступают одинаковые запросы, действия. Решить это можно, используя VPN.
- По капче. Ряд ресурсов при подозрении на автоматизацию процесса предлагают ее пройти. Обучение системы отгадывать и распознавать картинку – это дорогая и длительная процедура.

Как пользоваться парсером?
На начальных этапах парсинг пригодится для анализа конкурентов и подбора информации, необходимой для собственного проекта. В дальнейшей перспективе парсеры используются для актуализации материалов и аудита страниц.
При работе с парсером весь процесс строится вокруг вводимых параметров для поиска и извлечения контента. В зависимости от того, с какой целью планируется парсинг, будут возникать тонкости в определении вводных. Придется подгонять настройки поиска под конкретную задачу.
Иногда я буду упоминать названия облачных или десктопных парсеров, но использовать именно их необязательно. Краткие инструкции в этом параграфе подойдут практически под любой программный парсер.
Это наиболее частый сценарий использования утилит для автоматического сбора данных. В этом направлении обычно решаются сразу две задачи:
- актуализация информации о цене той или иной товарной единицы,
- парсинг каталога товаров с сайтов поставщиков или конкурентов.
В первом случае стоит воспользоваться утилитой Marketparser. Указать в ней код продукта и позволить самой собрать необходимую информацию с предложенных сайтов. Большая часть процесса будет протекать на автомате без вмешательства пользователя. Чтобы увеличить эффективность анализа информации, лучше сократить область поиска цен только страницами товаров (можно сузить поиск до определенной группы товаров).
Парсинг других частей сайта
Принцип поиска других данных практически не отличается от парсинга цен или адресов. Для начала нужно открыть утилиту для сбора информации, ввести туда код нужных элементов и запустить парсинг.
Разница заключается в первичной настройке. При вводе параметров для поиска надо указать программе, что рендеринг осуществляется с использованием JavaScript. Это необходимо, к примеру, для анализа статей или комментариев, которые появляются на экране только при прокрутке страницы. Парсер попытается сымитировать эту деятельность при включении настройки.
Также парсинг используют для сбора данных о структуре сайта. Благодаря элементам breadcrumbs, можно выяснить, как устроены ресурсы конкурентов. Это помогает новичкам при организации информации на собственном проекте.
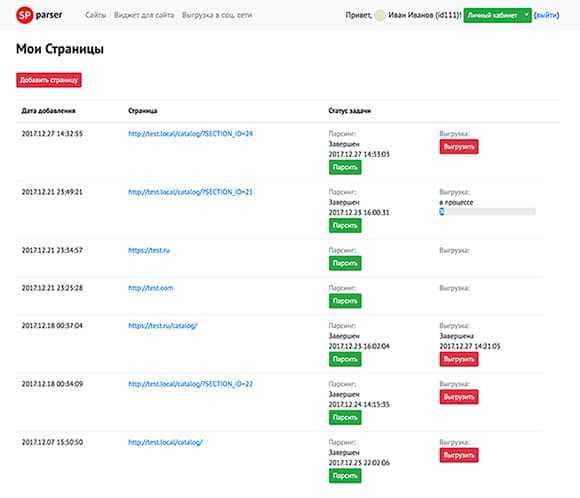
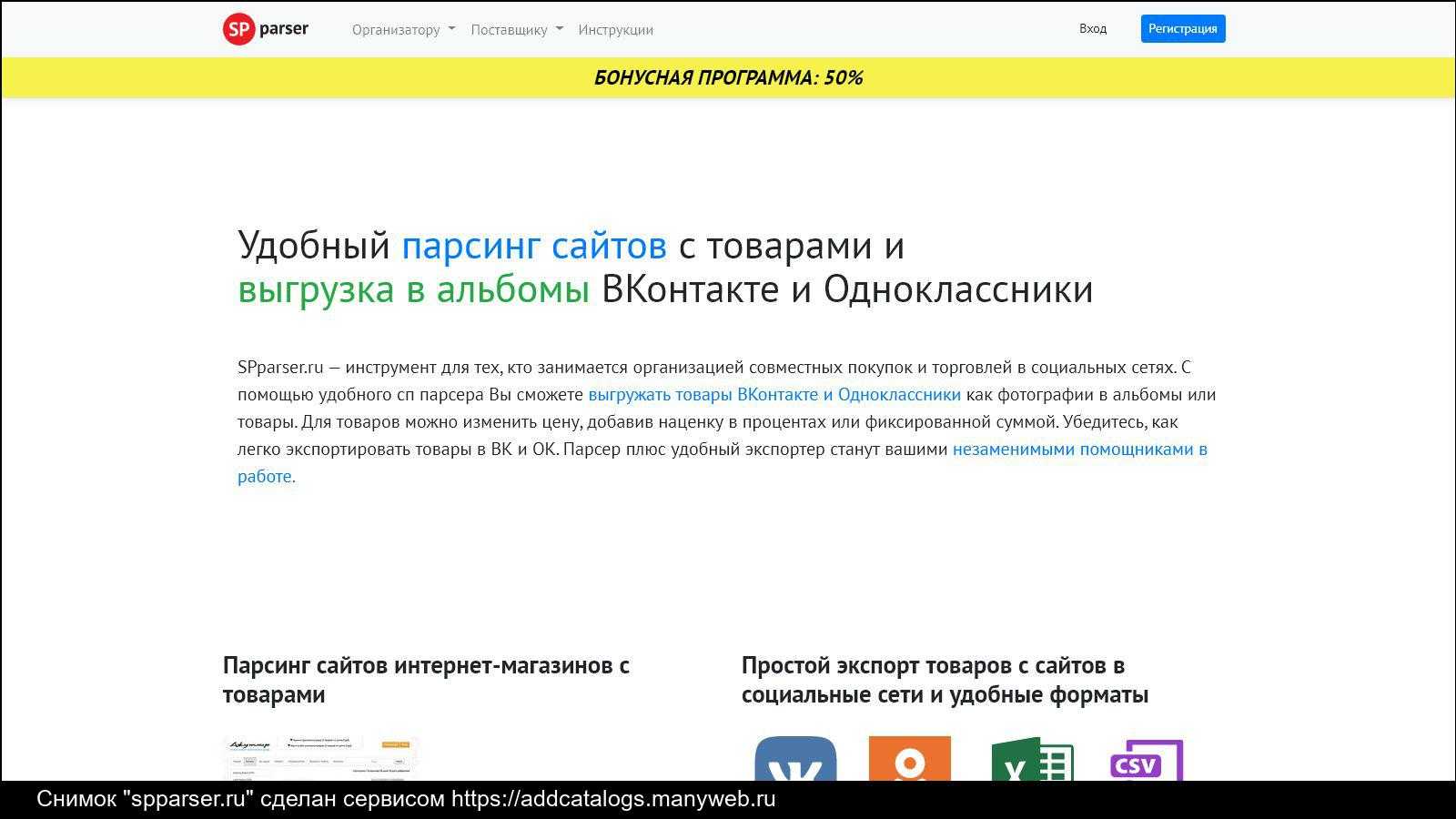
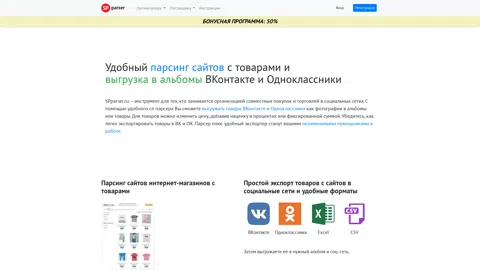
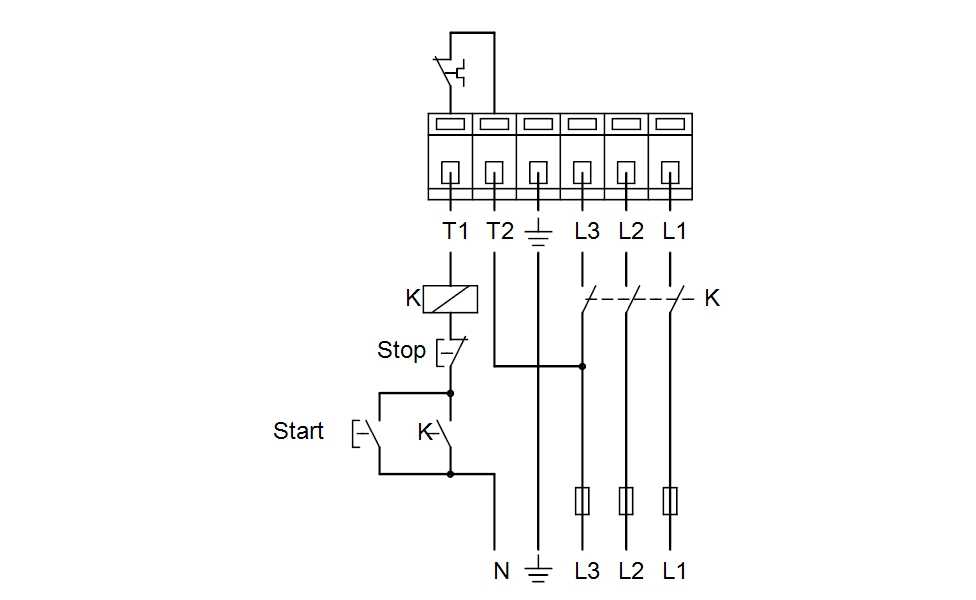
SPparser.ru — бесплатный парсер сайтов с товарами для СП плюс виджет для поставщиков. Автоматический экспорт в ВК и ОК. Для мобильного и компьютера
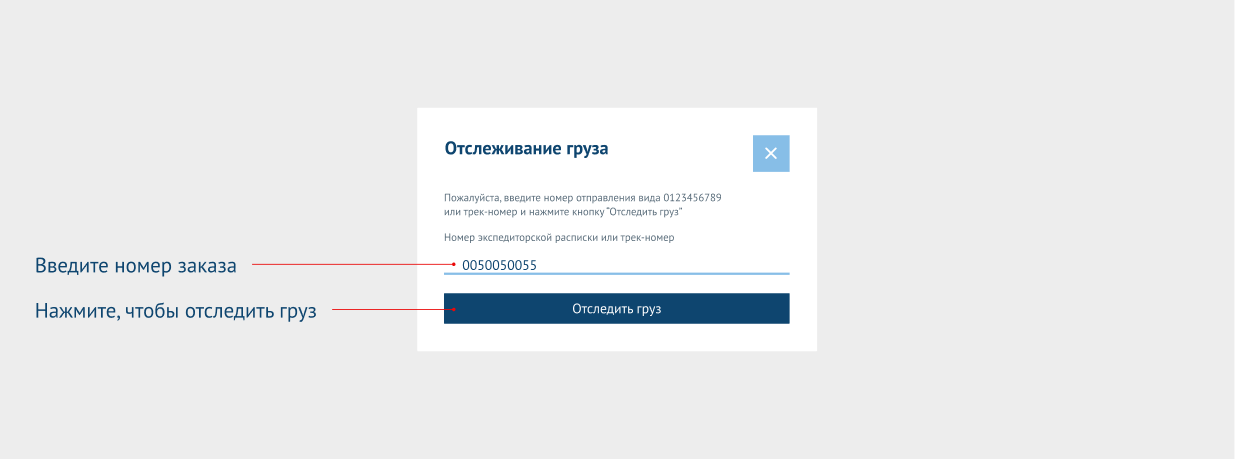
Тут все просто. Выбираете необходимую страницу с товарами.
Панель управления
С помощью удобной панели управления организатор СП может контролировать страницы, которые необходимо спарсить и выгрузить в соц. сети.
Выгрузка
На странице выгрузки вы можете настроить необходимые вам параметры, такие как свойства товара, а так же цену, указав желаемую наценку.
Для поставщиков
- Оплатите неограниченный доступ для ваших товаров организаторам СП
- Повысьте продажи и лояльность клиентов
- Удобный виджет
- Продвижение вашей продукции
- Вы знаете кто загружает ваши товары
- Турбо скорость у парсера
Для организаторов
- Экономия времени от 85% до 97%
- Автоматические выгрузки по расписанию
- Парсинг альбомов из ВК
- Парсинг альбомов из ОК
- Быстрый парсинг сайтов и выгрузка товаров
- Оперативное обновление информации
- Парсинг и загрузка выполняются в фоновом режиме
- Официальные совместные закупки
Елена Черкашина
организатор СП
С помощью СП Парсера загрузка фотографий в альбомы стала в разы быстрее!!))) Спасибо разработчикам за сервис. Рекомендую всем!!
Рекомендую всем!!
Анна Артемина
Юлия Кирова
организатор СП
Очень удобно! Простой, функциональный загрузчик и ничего лишнего. Оптимизировала своё время по наполнению альбомов товарами и занимаюсь более важными вещами.
Катя Липатова
организатор СП
Отзывчивая поддержка. Всем рекомендую!)) Простая и удобная настройка выгрузки.
Нина Федорова
организатор СП
У парсера есть возможность скопировать фотографии из альбомов ВКонтакте и выгрузить их в свои альбомы в Одноклассниках или в товары ВК. Это существенно ускоряет работу над поддержанием альбомов с товарами в актуальном состоянии. Парсер распознает цены, размеры и цветы. Можно добавить свою наценку и комментарии.
Попробовать прямо сейчас!
Подпишитесь на нашу группу, чтобы следить за свежими новостями:
Была потрясена нескончаемыми возможностями
Рекомендую
Хорошо
Надёжность
Удобство
Внешний вид
Поддержка
Функциональность
Минусы
Было бы здорово, если бы я в самом начале использования я посмотрела обучающее видео — это в конечном итоге сэкономило бы мне кучу времени
Использовала Серпстат во время изучения блока СЕО (в составе общего курса интернет-маркетинга), для выполнения домашних работ и курсовой. И была просто потрясена обилием функций, удобством и практически безграничными возможностями использования приложения в интернет-маркетинге. Именно благодаря Серпстату я получила истинное удовольствие при выполнении моей любимой работы, Прогноз Трафика («прощупывание» семантики, анализ конкурентов и тренда в целом). И осознала, в каком направлении планирую развиваться в интернет маркетинге в будущем!


Можно ли использовать парсеры
Распространено мнение, что парсинг сайтов как минимум неэтичен, а в некоторых случаях и незаконен. Действительно, парсеры собирают информацию с чужих веб-ресурсов, баз данных и других источников. Однако в большинстве случаев сведения находятся в открытом доступе, то есть использование программ не нарушает закон. Противозаконным может стать применение данных, например:
- для спам-рассылки и звонков. Это нарушает закон о защите персональных данных;
- копирование и использование информации с сайта-конкурента на собственном ресурсе. Это может нарушать авторские права.
В целом, парсинг не нарушает нормы законодательства и этики. Автоматизированный сбор информации позволяет сделать сайт и реализуемый с его помощью продукт более удобным для клиентов.
Другие термины на «П»
ПингПроксиПрефабПентестПротоколПайплайнПриложениеПеременнаяПолиморфизмПаттерн (шаблон)Программный кодПрограммированиеПоведенческие факторыПрограммное обеспечение
Все термины
Техническая информация
iСервер: nginx/1.20.1
iSpparser.ru создан 6 year(s) 3 month(s) 7 day(s) ago (2017-12-01)
iОкончание срока регистрации (2023-01-01)
iSpparser.ru зарегистрирован у регистратора REGRU-RU
iSpparser.ru зарегистрирован на Private Person
iКонтактная информация: http://www.reg.ru/whois/admin_contact
iNS сервера: ns1.timeweb.ru., ns2.timeweb.ru., ns3.timeweb.org., ns4.timeweb.org.
iIP версии 4: 109.68.212.109
iDNS TXT запись: «v=spf1 +mx +a:spparser.ru -all»»v=spf1 include:_spf.timeweb.ru ~all»
iDNS MX почтовая запись: 10 mx.yandex.net.
iDMARC почтовая антиспам запись: 109.68.212.109
iADSP почтовая запись: 109.68.212.109
iПолная информация из Whois
% TCI Whois Service. Terms of use: % https://tcinet.ru/documents/whois_ru_rf.pdf (in Russian) % https://tcinet.ru/documents/whois_su.pdf (in Russian) domain: SPPARSER.RU nserver: ns1.timeweb.ru. nserver: ns2.timeweb.ru. nserver: ns3.timeweb.org. nserver: ns4.timeweb.org. state: REGISTERED, DELEGATED, UNVERIFIED person: Private Person registrar: REGRU-RU admin-contact: http://www.reg.ru/whois/admin_contact created: 2017-12-01T12:26:30Z paid-till: 2022-12-01T12:26:30Z free-date: 2023-01-01 source: TCI Last updated on 2022-09-22T11:26:30Z
iПолная информация об IP 109.68.212.109
% This is the RIPE Database query service. % The objects are in RPSL format. % % The RIPE Database is subject to Terms and Conditions. % See http://www.ripe.net/db/support/db-terms-conditions.pdf % Note: this output has been filtered. % To receive output for a database update, use the "-B" flag. % Information related to '109.68.212.0 - 109.68.213.255' % Abuse contact for '109.68.212.0 - 109.68.213.255' is '' inetnum: 109.68.212.0 - 109.68.213.255 netname: TW-VDS geofeed: https://geofeed.timeweb.net/geofeed.csv country: RU admin-c: TMWB-RIPE tech-c: TMWB-RIPE status: ASSIGNED PA mnt-by: TIMEWEB-MNT created: 2020-02-05T12:05:42Z last-modified: 2022-09-02T13:30:44Z source: RIPE role: TimeWeb Co. Ltd. Role Account address: 22/2 lit.A,Zastavskaya str. address: 196006, Saint-Petersburg address: Russia phone: +7 812 2481081 phone: +7 495 0331081 abuse-mailbox: admin-c: AAB215-RIPE admin-c: KRON tech-c: AAB215-RIPE tech-c: AA39263-RIPE tech-c: AG26308-RIPE tech-c: KRON nic-hdl: TMWB-RIPE mnt-by: TIMEWEB-MNT created: 2008-03-18T10:36:42Z last-modified: 2022-03-05T06:49:37Z source: RIPE # Filtered % Information related to '109.68.212.0/24AS9123' route: 109.68.212.0/24 origin: AS9123 mnt-by: TIMEWEB-MNT created: 2020-01-24T08:59:56Z last-modified: 2022-09-02T12:27:17Z source: RIPE % This query was served by the RIPE Database Query Service version 1.103 (HEREFORD)
iПолная информация о DNS
A: 109.68.212.109 TXT: "v=spf1 +mx +a:spparser.ru -all" TXT: "v=spf1 include:_spf.timeweb.ru ~all" MX: 10 mx.yandex.net. DMARC: 109.68.212.109 ADSP: 109.68.212.109
Чек-лист по выбору парсера
Краткий чек-лист, который поможет выбрать наиболее подходящий инструмент или сервис.
- Четко определите, для каких задач вам нужен парсер: анализ SEO конкурентов или мониторинг цен, сбор данных для наполнения каталога, съем позиций и т.д.
- Определите, какой объем данных и в каком виде нужно получать.
- Определите, как часто вам нужно собирать данные: единоразово или с определенной периодичностью (раз в день/неделю/месяц).
- Выберите несколько инструментов, которые подходят для решения ваших задач. Попробуйте демо-версии. Узнайте, предоставляется ли техническая поддержка (желательно даже протестировать ее — задать парочку вопросов и посмотреть, как быстро вы получите ответ и насколько он будет исчерпывающим).
- Выберите наиболее подходящий сервис по соотношению цена/качество.
Для крупных проектов, где требуется парсить большие объемы данных и производить сложную обработку, более выгодной может оказаться разработка собственного парсера под конкретные задачи.
Для большинства же проектов достаточно будет стандартных решений (возможно, вам может быть достаточно бесплатной версии любого из парсеров или пробного периода).
Parsing
Данный механизм действует по заданной программе и сопоставляет определенный набор слов, с тем, что нашлось в интернете. Как поступать с полученной информацией, написано в командной строке, называемой «регулярное выражение». Она состоит из символов и задает правило поиска.
Фактически понятие переводится с английского языка как семантический анализ или разбор. Но термин, применяемый в технологиях создания и наполнения вебсайта, имеет более широкое значение. Это процедура, действие, предполагающее многостороннее исследование страницы, документа, целого раздела на предмет нахождения лексических, грамматических единиц или иных элементов (не только текста, но и видео-, аудио-контента) с последующей систематизацией. Искомые сведения находятся и преобразуются, они подготавливаются для дальнейшей работы с ними. Еще можно сказать, что это быстрая оценка и скорая обработка интернет-ресурса, данных с него. Вручную подобный процесс занял бы много времени, но автоматизация его значительно упрощает.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
Второе название для процедуры – скраппинг, или скрейпинг от англоязычного «scraping». В ходе этого буквального «соскабливания» программное обеспечение заходит на вебсайт под видом обыкновенного пользователя и, используя скрипты, производит сбор данных.
Исходником может быть ваш собственный веб-ресурс (для аналитики и принятия последующих решений), сайт конкурента, страничка из социальных сетей и пр. Полученным результатом можно будет пользоваться в дальнейшем по усмотрению владельца. Приведем понятный пример. По такому принципу работают поисковые системы, когда они анализируют страницы на релевантность, наличие ключевых слов из запроса и соответствие тематике, а затем на основе полученных сведений автоматически формируется выдача.

Поищите JSON в HTML коде страницы
Как было удобно с XHR запросами, да? Ощущение, что ты используешь официальное API. Приходит много данных, ты все сохраняешь в базу. Ты счастлив. Ты бог парсинга.
Но тут надо парсить другой сайт, а там нет нужных GET/POST запросов! Ну вот нет и все. И ты думаешь: неужели расчехлять XPath/CSS-selectors? Нет!
Чтобы страница хорошо проиндексировалась поисковиками, необходимо, чтобы в HTML коде уже содержалась вся полезная информация: поисковики не рендерят Javascript, довольствуясь только HTML. А значит, где-то в коде должны быть все данные.
Современные SSR-движки (server-side-rendering) оставляют внизу страницы JSON со всеми данные, добавленный бекендом при генерации страницы. Стоп, это же и есть ответ API, который нам нужен!
Вот несколько примеров, где такой клад может быть зарыт (не баньте, плиз):
Красивый JSON на главной странице Habr.com. Почти официальный API! Надеюсь, меня не забанят.И наш любимый (у парсеров) Linkedin!



Алгоритм действий такой:
-
В dev tools берете самый первый запрос, где браузер запрашивает HTML страницу (не код текущий уже отрендеренной страницы, а именно ответ GET запроса).
-
Внизу ищите длинную длинную строчку с данными.
-
Если нашли — повторяете у себя в парсере этот GET запрос страницы (без рендеринга headless браузерами). Просто.
-
Вырезаете JSON из HTML любыми костылямии (я использую ).
Популярные парсеры для SEO
PromoPult
Данный парсер метатегов и заголовков позволяет убрать дубли метатегов, а также выявить неинформативные заголовки, будучи особо полезным при анализе SEO конкурентов. Первые пятьсот запросов – бесплатно, а далее придется заплатить 0,01 рубля за запрос при объеме от десяти тысяч.
Работа сервиса происходит «в облаке», а для начала потребуется добавить список URL и указать страницы, парсинг которых следует осуществить. Благодаря данному парсеру можно проанализировать ключевые слова, используемые конкурентами с целью оптимизации страниц сайта, а также изучить, как происходит формирование заголовков.
Предназначен для комплексного анализа сайтов, что позволяет провести анализ основных SEO-параметров, осуществить технический анализ сайта, а также импортировать данные как из Google Аналитики, так и Яндекс.Метрики. Предоставляется тестовый период длительностью в 14 дней, а стоимость начинается от 19 долларов в месяц.
Screaming Frog SEO Spider
Данный парсер является идеальным решением для любых SEO-задач. Лицензию на год можно приобрести за 149 фунтов, однако есть и бесплатная версия, отличающаяся ограниченным функционалом, в то время как количество URL для парсинга не может превышать отметку в пятьсот.
ComparseR
С помощью данного десктопного парсера можно выявить страницы, которые обходит поисковый робот во время сканирования сайта, а также провести технический анализ портала. Есть демоверсия с некоторыми ограничениями, а лицензию можно приобрести за две тысячи рублей.
Анализ от PR-CY
Представляет собой онлайн-ресурс для анализа сайтов по достаточно подробному списку параметров. Минимальный тариф составляет 990 рублей в месяц, а тестирование, с полным доступом к функционалу, можно провести в течение семи дней.
Анализ от SE Ranking
Стоимость минимального тарифа данного облачного сервиса составляет от семи долларов в месяц, при оформлении годовой подписки, причем возможна как подписка, так и оплата за каждую проверку. Сервис позволяет проверить скорость загрузки страниц, проанализировать метатеги. Выявить технические ошибки, а также провести анализ внутренних ссылок.
Xenu`s Link Sleuth
Данный бесплатный десктопный парсер предназначен для Windows и используется для парсинга всех URL, имеющихся на сайте, а также применяется с целью обнаружения неработающих ссылок.
Представляет собой SEO-комбайн, отличающийся многофункциональностью, причем минимальный тарифный план лицензии, носящей пожизненный характер, составляет 119 долларов, в то время как максимальный – 279. Демоверсия присутствует. Данный инструмент позволяет осуществить парсинг ключевых слов и провести мониторинг позиций, занимаемых сайтом в поисковых системах.
Виды парсеров по сферам применения
Для организаторов СП (совместных покупок)
Есть специализированные парсеры для организаторов совместных покупок (СП). Их устанавливают на свои сайты производители товаров (например, одежды). И любой желающий может прямо на сайте воспользоваться парсером и выгрузить весь ассортимент.
Чем удобны эти парсеры:
- интуитивно понятный интерфейс;
- возможность выгружать отдельные товары, разделы или весь каталог;
- можно выгружать данные в удобном формате. Например, в Облачном парсере доступно большое количество форматов выгрузки, кроме стандартных XLSX и CSV: адаптированный прайс для Tiu.ru, выгрузка для Яндекс.Маркета и т. д.
Популярные парсеры для СП:
- SPparser.ru,
- Облачный парсер,
- Турбо.Парсер,
- PARSER.PLUS,
- Q-Parser.
Вот три таких инструмента:
- Marketparser,
- Xmldatafeed,
- ALL RIVAL.
Парсеры для быстрого наполнения сайтов
Такие сервисы собирают названия товаров, описания, цены, изображения и другие данные с сайтов-доноров. Затем выгружают их в файл или сразу загружают на ваш сайт. Это существенно ускоряет работу по наполнению сайта и экономят массу времени, которое вы потратили бы на ручное наполнение.
В подобных парсерах можно автоматически добавлять свою наценку (например, если вы парсите данные с сайта поставщика с оптовыми ценами). Также можно настраивать автоматический сбор или обновление данных по расписания.
Примеры таких парсеров:
- Catalogloader,
- Xmldatafeed,
- Диггернаут.
Какие задачи помогает решить парсер?
При желании парсер можно сподобить к поиску и извлечению любой информации с сайта, но есть ряд направлений, в которых такого рода инструменты используются чаще всего:
- Мониторинг цен. Например, для отслеживания изменения стоимости товаров у магазинов-конкурентов. Можно парсить цену, чтобы скорректировать ее на своем ресурсе или предложить клиентам скидку. Также парсер цен используется для актуализации стоимости товаров в соответствии с данными на сайтах поставщиков.
- Поиск товарных позиций. Полезная опция на тот случай, если сайт поставщика не дает возможности быстро и автоматически перенести базу данных с товарами. Можно самостоятельно «запарсить» информацию по нужным критериям и перенести ее на свой сайт. Не придется копировать данные о каждой товарной единице вручную.
- Извлечение метаданных. Специалисты по SEO-продвижению используют парсеры, чтобы скопировать у конкурентов содержимое тегов title, description и т.п. Парсинг ключевых слов – один из наиболее распространенных методов аудита чужого сайта. Он помогает быстро внести нужные изменения в SEO для ускоренного и максимально эффективного продвижения ресурса.
- Аудит ссылок. Парсеры иногда задействуют для поиска проблем на странице. Вебмастера настраивают их под поиск конкретных ошибок и запускают, чтобы в автоматическом режиме выявить все нерабочие страницы и ссылки.
Серый парсинг
Такой метод сбора информации не всегда допустим. Нет, «черных» и полностью запрещенных техник не существует, но для некоторых целей использование парсеров считается нечестным и неэтичным. Это касается копирования целых страниц и даже сайтов (когда вы парсите данные конкурентов и извлекаете сразу всю информацию с ресурса), а также агрессивного сбора контактов с площадок для размещения отзывов и картографических сервисов.
Но дело не в парсинге как таковом, а в том, как вебмастера распоряжаются добытым контентом. Если вы буквально «украдете» чужой сайт и автоматически сделаете его копию, то у хозяев оригинального ресурса могут возникнуть вопросы, ведь авторское право никто не отменял. За это можно понести реальное наказание.
Добытые с помощью парсинга номера и адреса используют для спам-рассылок и звонков, что попадает под закон о персональных данных.
Абсолютно сырой и ненужный продукт. Невменяемая поддержка.
Плохо
Надёжность
Поддержка
Функциональность
Минусы
«У вас на странице 4 ссылки 404.» «Какие именно, покажите, там 80 ссылок на странице.» «Мы не можем показать, какие именно, мы только знаем, что их там 4.» И зачем мне такой «сервис»?





Поддержка изо всех сил старается говорить на английском, который знает плохо. Предложил на русский перейти — нет, ни за что. Будем дальше позориться. Запросил возврат средств, так как сервис сырой и особой пользы не приносит, и началось…
Короче, интерфейс нарисовать нарисовали, но толком ничего не работает. Ощущение недоделанности во всем. В отчетах рисуются красным проблемы, но не говорится, как их решить. Поддержка бедовая, пишет повести о том, какие они крутые, вместо ответа на конкретно поставленный технический вопрос. Еле выбил деньги обратно, помогла только угроза открыть клейм в Пейпале.
Такое чувство, что все положительные отзывы оставлены аффилиатами, которые воспевают продукт за мзду.
Парсеры поисковых систем#
| Название парсера | Описание |
|---|---|
| SE::Google | Парсинг всех данных с поисковой выдачи Google: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Многопоточность, обход ReCaptcha |
| SE::Yandex | Парсинг всех данных с поисковой выдачи Yandex: ссылки, анкоры, сниппеты, Related keywords, парсинг рекламных блоков. Максимальная глубина парсинга |
| SE::AOL | Парсинг всех данных с поисковой выдачи AOL: ссылки, анкоры, сниппеты |
| SE::Bing | Парсинг всех данных с поисковой выдачи Bing: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Baidu | Парсинг всех данных с поисковой выдачи Baidu: ссылки, анкоры, сниппеты, Related keywords |
| SE::Dogpile | Парсинг всех данных с поисковой выдачи Dogpile: ссылки, анкоры, сниппеты, Related keywords |
| SE::DuckDuckGo | Парсинг всех данных с поисковой выдачи DuckDuckGo: ссылки, анкоры, сниппеты |
| SE::MailRu | Парсинг всех данных с поисковой выдачи MailRu: ссылки, анкоры, сниппеты |
| SE::Seznam | Парсер чешской поисковой системы seznam.cz: ссылки, анкоры, сниппеты, Related keywords |
| SE::Yahoo | Парсинг всех данных с поисковой выдачи Yahoo: ссылки, анкоры, сниппеты, Related keywords, Максимальная глубина парсинга |
| SE::Youtube | Парсинг данных с поисковой выдачи Youtube: ссылки, название, описание, имя пользователя, ссылка на превью картинки, кол-во просмотров, длина видеоролика |
| SE::Ask | Парсер американской поисковой выдачи Google через Ask.com: ссылки, анкоры, сниппеты, Related keywords |
| SE::Rambler | Парсинг всех данных с поисковой выдачи Rambler: ссылки, анкоры, сниппеты |
| SE::Startpage | Парсинг всех данных с поисковой выдачи Startpage: ссылки, анкоры, сниппеты |
Как работает парсер
Термин «парсинг» произошел от английского глагола to parse, означающего в переводе с английского «по частям». Процесс представляет собой синтаксический анализ любого набора связанных друг с другом данных. В общем виде парсинг выполняется в несколько этапов:
- Сканирование исходного массива информации (HTML-кода, текста, базы данных и т.д.).
- Вычленение семантически значимых единиц по заданным параметрам — например заголовков, ссылок, абзацев, выделенных жирным шрифтом фрагментов, пунктов меню.
- Конвертация полученных данных в формат, удобный для изучения, а также их систематизация в виде таблиц или отчетов для дальнейшего использования.
Объектом парсинга может быть любая грамматически структурированная система: информация, закодированная естественным языком, языком программирования, математическими выражениями и т.д. Например, если исходный массив данных представляет собой HTML-страницу, парсер может вычленить из кода информацию и перевести ее в текст, понятный для человека. Или конвертировать в JSON — формат для приложений и скриптов.
Доступ парсера к сайту возможен:
- через протоколы HTTP, HTTPS или веб-браузер;
- с использованием бота, имеющего права администратора.
Получение данных парсером — семантический анализ исходного массива информации. Программа разбивает его на отдельные части (лексемы): слова, словосочетания и т.д. Парсер проводит их грамматический анализ, преобразуя линейную структуру текста в древовидную (синтаксическое дерево). Такая форма упрощает «понимание» информационного массива компьютерной программой и бывает двух типов:
- дерево зависимостей — такая структура состоит из компонентов, находящихся в иерархических отношениях друг к другу;
- дерево составляющих — в структуре этого типа компоненты находятся в тесной зависимости друг с другом, но без иерархических отношений.
Также результат работы парсера может представлять собой сочетание моделей. Программа действует по одному из двух алгоритмов:
- Нисходящий парсинг. Анализ осуществляется от общего к частному, а синтаксическое дерево разрастается вниз.
- Восходящий парсинг. Анализ и построение синтаксического дерева осуществляются снизу вверх.
Выбор конкретного метода парсинга зависит от конечной цели. В любом случае, парсер должен уметь вычленять из общего массива только необходимые данные, а также преобразовывать их в удобный для решения задачи формат.
Станьте веб-разработчиком и найдите стабильную работу на удаленке
Подробнее