
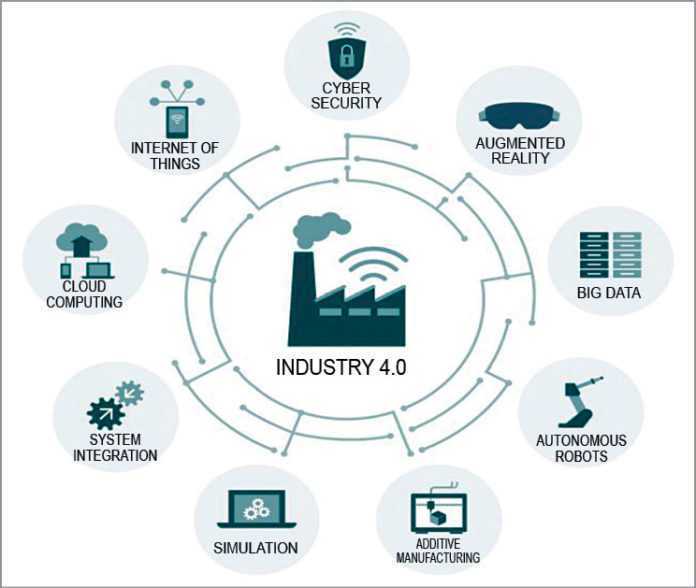
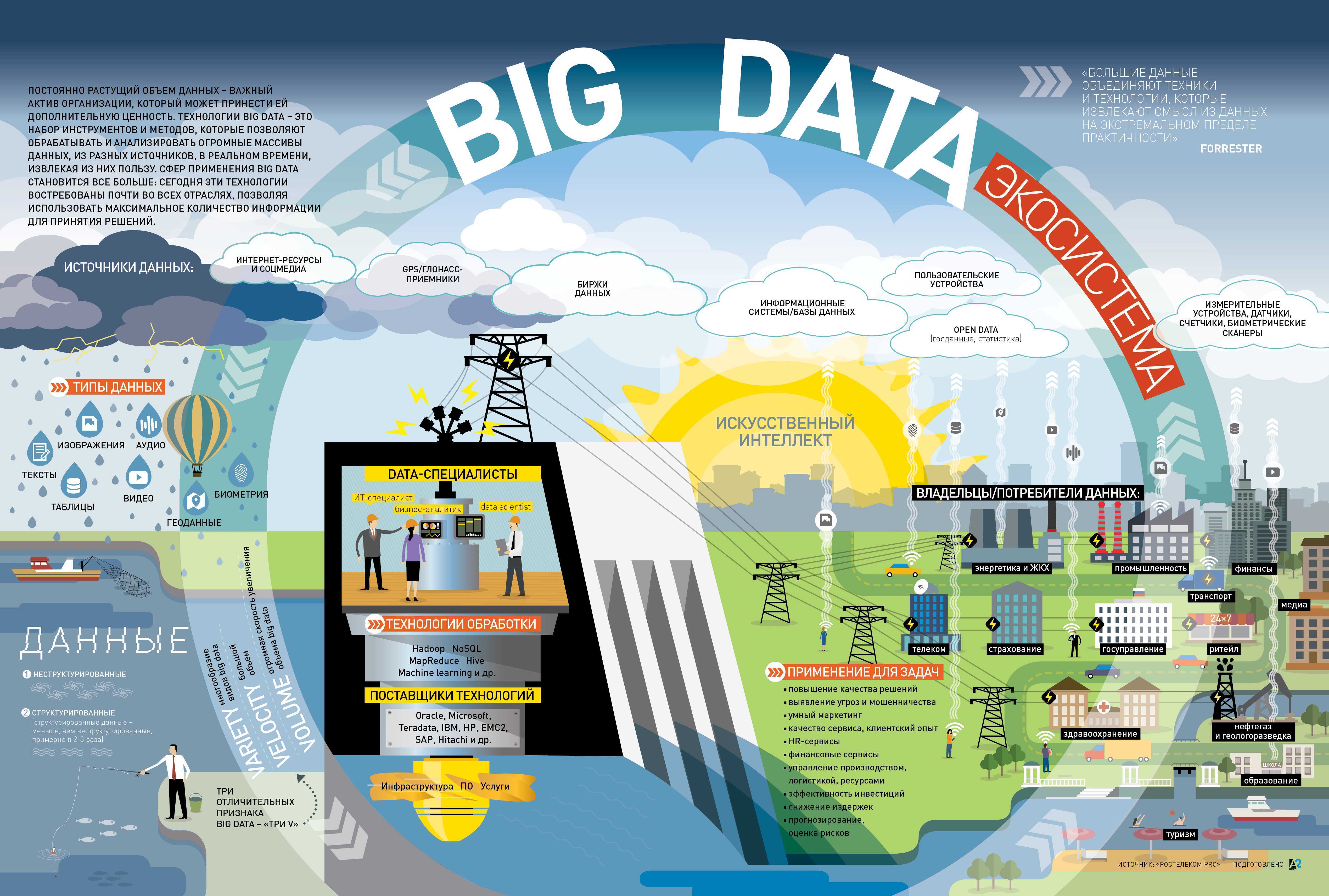
Где применяется Big Data
Наверняка у большинства из нас при упоминании понятия «большие данные» в голове возникает огромное помещение, заставленное множеством серверов с мигающими огоньками
Но чтобы понять, что речь идет о действительно важном феномене, изменившем правила игры, достаточно обратиться к нескольким примерам
Недавние выборы президента США показали, насколько эффективным может оказаться применение новейших информационных технологий
В то время как Хиллари Клинтон прибегала к традиционным методам и привлекала в свой штаб знаменитостей, команда Дональда Трампа решила сфокусировать внимание на изучении предпочтений и потребительского поведения миллионов американцев. Получив точные данные о том, чего хочет электорат, штаб кандидата от республиканцев смог более эффективно отвечать на запросы активных пользователей Интернета
В итоге победа Трампа не выглядит такой уж неожиданной, если принять во внимание то, какая большая и результативная работа была проделана.

Или возьмем, к примеру, стриминг-сервис Netflix, который за последние годы стал одним из самых популярных производителей контента
Поставляя видеоматериалы зрителям, компания успела накопить гигантский объем статистических данных, досконально изучив предпочтения пользователей: какие сюжеты им больше по душе, каких актеров они любят, какие сцены пересматривают несколько раз, а какие пропускают. В итоге каждый новый сериал Netflix попадает в точку и зарабатывает самые высокие рейтинги на IMDB. Если вы по-прежнему считаете, что залог успеха состоит в таланте шоураннеров, то, скорее всего, вы слишком наивны.
В микроскопическом масштабе большие данные можно поставить на службу вашему самосовершенствованию. Например, ваш фитнес-браслет или умные часы может собирать информацию о потребляемых калориях, пройденном расстоянии, сердечном пульсе, а также статистику сна. Сбор и анализ таких сведений позволит вам скорректировать свои привычки, что при должном терпении должно будет позитивно сказаться на вашем здоровье и долголетии.
Кстати, и в глобальном масштабе большие данные активно помогают медицине. Уже сейчас обработка накопленных статистических данных позволяет не только в считанные минуты с высокой точностью диагностировать различные заболевания, но и эффективно прогнозировать их возникновения. Это должно будет обезопасить людей от затаившейся угрозы и спасти миллионы жизней.
Один из ярких тому примеров — платформа ResearchKit, которую компания Apple запустила в 2016 году. Благодаря использованию мобильных приложений медицинские специалисты собирают данные о состоянии здоровья пользователей. Это позволяет не только распространять уход за больными за пределы клиники и обеспечивать их скорейшее выздоровление, но и накапливать необходимые данные для повышения эффективности взаимодействия с будущими пациентами.
Разумеется, большими данными активно пользуются и правоохранительные органы. Например, Агентство национальной безопасности США использует имеющимися данными для выявления и предупреждения террористической активности. Корпорации давно пользуются решениями в этой области для профилактики кибератак и несанкционированных проникновений в системы. Полиция тоже экспериментирует с Big Data, пытаясь на основании информации из публичных профилей определять потенциальную угрозу для правопорядка того или иного гражданина.
Здесь нелишним будет вспомнить показательную историю 2014 года, когда чикагская полиция при помощи компьютерной системы составила список из 400 жителей города, которые имеют все предпосылки для того, чтобы нарушить закон. Полицейские посетили этих граждан и провели с ними профилактические беседы, однако история наделала много шума, в первую очередь из-за бесцеремонного вторжения в личную жизнь. Хотя проект со скандалом закрыли, нет никаких свидетельств того, что компьютерный анализ потенциальных криминальных наклонностей граждан был прекращен.
Хотя эпоха больших данных все еще находится на начальной стадии, достижениями этой дисциплины уже активно пользуются как частные корпорации, так и правительства. Но главное, чтобы этот ценный актив не оказался в распоряжении тех, кто мог бы использовать его во вред человечеству.
Где применяется аналитика больших данных?
Big Data становится важным инструментом построения бизнес-стратегий и маркетинга. Чем больше информации можно обработать, тем точнее будут полученные результаты. На основе объёмных сведений анализируют требования клиентов к существующим продуктам, создают проекты с высоким потенциалом популярности.
В рамках любой компании большие данные помогают вести анализ в трёх аспектах:
- общая картина бизнеса с точки зрения цифр;
- оценка конкурентов;
- изучение клиентов и целевой аудитории.
Крупные IT и финансовые корпорации через обработку объёмных массивов информации предотвращают мошеннические операции и утечку персональных сведений. Государственные структуры оценивают эффективность выполнения социальных и экономических программ. Игровая индустрия анализирует поведение и предпочтения игроков, разрабатывает инструменты привлечения и удержания.
Внутри корпоративной структуры Big Data используется подразделениями внутреннего контроля и аудита, отделами оптимизации и оценки эффективности деятельности компании. Рост информационных потоков в ближайшем будущем приведёт к работе с большими данными даже в сегменте малого и среднего бизнеса. С учётом готовых веб-инструментов им не придётся нанимать IT-специалиста. Достаточно разобраться в принципах работы с Big Data и изучить функциональность Big Data Tools.
Продукты из этой статьи:
SberDataExchange
Big data в образовании: помощь в выборе курсов и предотвращение отчислений
Помощь в выборе курсов. В образовании проекты big data помогают студентам с профориентацией: анализируют их способности и помогают выбрать направление обучения и будущую профессию.
Так, в американском университете Остин Пии разработали рекомендательную систему подбора курсов. Она собирает данные об успеваемости, находит «похожих» студентов, и на основе этого подбирает курсы для конкретного человека. Предсказания устраивают студентов в 90% случаев.
Предотвращение отчислений. В США из университетов отчисляются 400 тысяч студентов в год. Чтобы решить эту проблему, в Университете Содружества Виргинии проанализировали данные об отчислениях и построили алгоритм, который выявляет студентов в группе риска.
Система оповещает, когда студент становится проблемным. И тогда с ним работают индивидуально, например, предлагают перевод на другой курс или помощь репетитора. По итогам семестра число студентов, закончивших курс, увеличилось на 16%.
Примеры решаемых задач
Обработка текстовой информации на естественном языке, как известно – одна из самых сложных задач Data Mining. Команда «Билайна» пользуется как «классикой жанра» (Bag of Words – мешок слов, TF-IDF), так и более новыми методами Deep Learning – например, поиск синонимов осуществляется при помощи структуры данных word2vec, библиотек Natural Language Toolkit и готовых алгоритмов Apache Spark.
Задачи на графах (Social Network Analysis)
Задачи на графах (а конкретнее – анализ социальных сетей в широком смысле этого слова) весьма требовательны к ресурсам, но «изобретать велосипед» специалистам не нужно: в Apache Spark уже реализована часть алгоритмов, которые активно и успешно используются в «Билайне». Плюс, конечно, собственные алгоритмы для более специфических задач – вообще же анализ социальных сетей нужен для верного построения маркетинговой политики: если знать, с кем крепче всего «связаны» лояльные клиенты (не обязательно самого оператора сотовой связи – речь может идти, например, о новом тарифном плане), то можно определить группу потенциальных клиентов, которые наиболее лояльно отнесутся к маркетинговым акциям.
Задачи прогнозирования (Predictive Modeling)
Постановка задачи прогнозирования или классификации, говоря бизнес-языком, выглядит достаточно просто. Допустим, мы имеем набор объектов (абонентов) и множество описывающих их признаков (пол, возраст, регион проживания и т. д.). Из набора объектов мы выделяем поднабор – так называемую обучающую выборку, – для каждого объекта которого известно значение целевой переменной (то есть ответ на некий интересующий нас вопрос – вероятность ухода конкретного абонента в отток, перехода на другой тарифный план и т.п.). Собственно задача прогнозирования заключается в том, чтобы предсказать значение целевой переменной для всего остального набора данных. Все это используется для таргетированных маркетинговых кампаний, а с практической точки зрения специалисты «Билайна» используют нейронные сети, деревья решений, композиции алгоритмов. В этом им помогает язык Python с его многочисленными библиотеками, ну а если обучающая выборка подходит под определение больших данных, то обращаются к Apache Spark или Vowpal Wabbit.
Задачи кластеризации (Cluster Analysis)
В случае кластерного анализа (задач кластеризации), в отличие от задач прогнозирования (классификации), обучающей выборки специалисты «на руках» не имеют. Типичная задача – поиск закономерностей в неразмеченных данных, то есть таком наборе объектов, для которого есть соответствующее множество признаков, однако конкретного соответствия ни для одного объекта не имеется. Кластерный анализ отвечает на вопрос, можно ли разделить набор данных на так называемые кластеры, то есть поднаборы данных, внутри которых объекты обладают сходными признаками. В «Билайне» кластерный анализ используется для сегментации абонентской базы, в ходе которой изучаются особенности конкретного сегмента (при помощи вышеописанных задач прогнозирования). Среди конкретных методов – классический алгоритм K-средних и более продвинутые методы кластеризации на графах и иерархической кластеризации.
Перспективы big data
Сейчас почти все крупные компании используют большие данные: собирают их, анализируют, применяют в связке с другими технологиями. По данным отчетов, рынок big data будет расти на 12,3% в год, чтобы к 2027 достигнуть 105,08 млрд.
Сейчас с big data в основном работают крупные предприятия — они занимают около 60% рынка. Но по оценкам экспертов, сегмент средних и малых предприятий до 2027 года тоже будет расти, со временем большие данные перестанут быть прерогативой больших компаний.
Для работы с большими данными необязательно строить свою инфраструктуру и тратить деньги на ее обслуживание. Можно арендовать готовое решение в облаке. Например, платформа VK Cloud (бывш. MCS) позволяет хранить, обрабатывать и анализировать данные, используя в том числе машинное обучение и инструменты визуализации. При этом вы платите только за используемые вычислительные мощности.
Правда, что смартфоны нас прослушивают? Это опасно?
Однажды наткнулся на комментарий, как какой-то человек пришел домой, увидел, что у него закончилась зубная паста, громко об этом воскликнул, и потом ему в интернете пошла реклама с доставкой зубной пасты на дом. В рамках этой истории можно сказать, что если в этот момент человек не общался с голосовым помощником, если у него не были включены умные устройства и другие девайсы, то я склонен считать, что это простое совпадение. Если он общался в этот момент, например, с голосовым помощником, то это в целом подтвержденная история, в том числе и самими компаниями. Они используют такие данные, чтобы улучшать качество своего сервиса. Опасно ли это? Я бы относился к этому так — если это мне не вредит, если это направлено на то, чтобы сделать мой клиентский путь проще, сделать сервисы лучше, а не дополнить мое «личное дело», то ничего плохого в этом нет.
Где в реальном мире можно найти Big Data?
Сами по себе «большие данные» – это технологии обработки больших массивов данных, которые могут быть неоднородными по своей структуре. Самый простой пример из практики – те же «Яндекс.Пробки», которые в режиме реального времени отслеживают данные геолокации своих пользователей – расположение, направление движения, скорость, а также связывают это с другими данными. В итоге сервис знает, где сейчас движение затруднено из-за пробок, и даже может их прогнозировать.
На самом же деле, примеров Big Data в жизни гораздо больше, вот то, о чем рассказали опрошенные нами эксперты:
- один из трех крупнейших сотовых операторов годами собирает разные данные абонентов – отслеживает род деятельности, привычки, уровень доходов, принадлежность к тем или иным социальным группам, вероятность попасть в ЧП, и т.д. Благодаря этому, отмечает Александр Богуцкий, оператор может делать разные интересные предложения для абонентов, быстро «погашать» конфликтные ситуации, а еще следить за качеством связи;
- банки отслеживают транзакции с карт своих клиентов. Если, например, клиент внезапно рассчитается картой в совсем непривычной для него локации, если по карте идет дубль операции, повторяются суммы сделок, и т.д., то банк заподозрит неладное и заблокирует карту, говорит Максим Буртиков из координационного центра RIPE NCC. Без специальных инструментов Big Data отследить весь поток операций было бы невозможно;
- торговые сети анализируют активность покупателей, и могут организовать поставки продуктов так, чтобы их хватило на всех клиентов, но при этом не осталось просроченных товаров, приводит пример Алексей Чащегоров. При этом магазины даже одной сети могут сильно отличаться по структуре и объему потребления продуктов, поэтому без особых методов анализа тоже не обойтись;
- метеорологические службы тоже используют массу разных параметров, чтобы сделать прогноз погоды более точным, и тем самым снизить последствия экологических катастроф, подготовиться к ураганам и штормам, вовремя эвакуировать людей из зоны возможного бедствия, говорит Михаил Попов из TalkBank;
- банки при оценке кредитоспособности заемщика могут оценить большой массив данных, определив вероятность того, что конкретный клиент когда-нибудь выйдет на просрочку или по какой-то причине не сможет выплачивать долг, говорит Алексей Рыбаков из компании Omega. При этом банку нужно проанализировать такой объем данных, что стандартными инструментами кредитного скоринга сделать невозможно.
Другими словами, Big Data есть везде, где нужно проанализировать большой объем разных данных и сделать какой-то конкретный вывод из них. Более того, компания может и не объявлять, что использует технологии Big Data – но по факту она все равно может применять полученную информацию в своих целях.
Хороший пример – еще в 2011 году один студент из Австрии запросил у Facebook всю собранную соцсетью информацию о нем. Как результат – компания прислала на CD-диске PDF-файл на 1200 страниц, в котором вся информация была разбита на 57 категорий (например, информация о работе, образовании, друзьях, политических предпочтениях и т.д.). Более того, Facebook собирал даже удаленные сообщения и имена бывших друзей, а часть информации вообще не попала в документ. По словам пользователя, соцсеть знает о пользователях больше, чем КГБ знала о советских гражданах.
Сейчас же технологии шагнули еще дальше, и тот же Facebook явно собирает куда больше, и как соцсеть использует эти данные – только Марку Цукербергу известно.
Другие компании достаточно открыто рассказывают о том, как они используют результаты анализа таких массивов данных, говорит Александр Богуцкий:
Других примеров можно найти массу – страховые компании оценивают индивидуальные риски клиентов и определяют страховую премию, учитывая разную информацию, международные организации используют статистические данные, чтобы помогать в борьбе с бедностью, преступностью и стихийными бедствиями, и т.д. Но больше всего Big Data интересуются правительства.
Примеры успешных проектов блокчейна и больших данных
На сегодняшний день можно выделить ряд проектов, успешно сочетающих технологии блокчейна и больших данных.
- Во-первых, это сервис Provenance, с помощью которого розничные продавцы и потребители получают проверенную информацию о том, из чего сделан продукт, откуда он поступил и как влияет на окружающую среду.
- Во-вторых, это децентрализованная сеть Datum, управляемая токеном доступа к данным (DAT). Она помогает пользователям монетизировать персональные данные.
- Следующий пример удачного альянса блокчейна и больших данных — стартап Omnilytics. Используя искусственный интеллект и принцип машинного обучения, система с помощью смарт-контрактов выполняет финансовую проверку и аудит, прогнозирует тенденции на рынке в разных отраслях.
- И, наконец, Filecoin — это проект с открытым кодом, облачное децентрализованное хранилище с защитой от несанкционированного доступа.
Примеры использования Big Data
Для того, чтобы вам не было скучно, давайте рассмотрим реальные примеры из разных сфер.
Бизнес
- Amazon использует big data для изучения корзин покупателей, рекомендаций, ценообразования, таргетинга рекламы, логистики
- Netflix использует big data аналитику для персонализированных рекомендаций фильмов и сериалов.
Сфера науки
- В проекте Большого адронного коллайдера данные нужны для изучения столкновений частиц, поиска бозона Хиггса и темной материи
- Проект SETI применяет большие данные для поиска разумной жизни во Вселенной.
Медицина
- В проекте по расшифровке генома человека Большие данные применяются для анализа ДНК и выявления генетических причин заболеваний
- IBM Watson Health использует big data для персонализированной медицины
- Компания Apple использовала инструменты Big Data на массивах медицинских данных, чтобы внедрить функцию ЭКГ в Apple Watch.
Образование
- Платформа Coursera анализирует поведение студентов онлайн-курсов, чтобы дать им обратную связь
- Платформа Khan Academy применяет ее для анализа успеваемости и составления индивидуальных планов для студентов.
Сфера безопасности
- Агентство национальной безопасности США использует Big Data для борьбы с терроризмом, хакерством и мошенничеством путем анализа коммуникаций на предмет выявления подозрительных лиц и действий.
- Splunk предлагает платформу для обработки и анализа больших данных в реальном времени. Они помогают организациям обнаруживать и реагировать на киберугрозы, создавать аналитические отчеты и мониторить безопасность своих сетей и систем.
Big data в промышленности: предсказание аварий и оптимизация производства
Например, у «Газпром нефти» сбоил автоматический перезапуск насосов после аварийного отключения электричества. Разобраться в проблеме помогли большие данные. Аналитики собрали 200 миллионов записей с контроллеров систем управления, проанализировали их, смоделировали события и выявили неожиданные причинно-следственные связи. В итоге сбои удалось прекратить.
Снижение стоимости продукции и оптимизация производства. Если собрать много данных о работе станков, проценте брака и каждом этапе производства, а потом их проанализировать, можно понять:
- при каких условиях чаще всего происходит брак;
- на какие этапы производства тратится больше всего времени и почему;
- какие тесты продукции малополезны и не дают новой информации;
- как можно оптимизировать и ускорить работу на отдельных этапах;
- как использовать меньше расходных материалов.
Все это помогает уменьшить издержки и снизить стоимость производства, а значит, повысить прибыль.
Например, компания Intel производит процессоры. Перед поставкой в магазин каждый процессор должен пройти примерно 19 000 тестов — это долго и дорого. Анализ данных всего производственного процесса , какие тесты избыточные. В итоге на них удалось сэкономить около 30 миллионов долларов.



Поиск новых месторождений. При добыче природных ресурсов месторождения часто приходится искать почти вслепую. Однако с помощью анализа больших данных можно обнаруживать закономерности, изучать состояние почв, наличие подземных пустот, температуру пород — и таким образом эффективно искать перспективные месторождения, сравнивая новые участки с уже известными аналогами.
Так, ООО НПЦ «Геостра» занимается обработкой и интерпретацией больших объемов данных, полученных в ходе поиска нефтяных месторождений. В качестве пилотного проекта на облачную платформу VK Cloud (бывш. MCS) перенесли геофизическое ПО для обработки высокоплотных геофизических данных. Проект оказался успешным: облачные вычислительные мощности справились с поставленной задачей.
Big data в маркетинге
Благодаря Big data маркетологи получили отличный инструмент, который не только помогает в работе, но и прогнозирует результаты. Например, с помощью анализа данных можно вывести рекламу только заинтересованной в продукте аудитории, основываясь на модели RTB-аукциона.
Big data позволяет маркетологам узнать своих потребителей и привлекать новую целевую аудиторию, оценить удовлетворённость клиентов, применять новые способы увеличения лояльности клиентов и реализовывать проекты, которые будут пользоваться спросом.
Сервис Google.Trends вам в помощь, если нужен прогноз сезонной активности спроса. Всё, что надо — сопоставить сведения с данными сайта и составить план распределения рекламного бюджета.
Принципы Big Data (MapReduce, NoSQL, Hadoop)
В отличие от традиционных средств обработки информации, данные Big Data невозможно обрабатывать на одном компьютере и, тем более, в Excel.
Чтобы можно было просчитать любой массив больших данных, необходимо выполнение ряда условий. Во-первых, это масштабируемость системы. В каждом кластере аппаратная поддержка должна увеличиваться пропорционально объему данных. Увеличились данные — выросло количество железа. Из этого следует второе условие — отказоустойчивость системы. При использовании большого количества компьютеров, вероятность выхода из строя одного из них — достаточно велика и это событие не должно влиять на систему.
Например, в кластере сети Facebook используется около 2 тыс. узлов на 21 Пбайт, а в eBay — 700 узлов на 16 Пбайт.
По возможности, все данные подчинены принципу локальности — чтобы избежать затрат ресурсов на трансфер биг даты. Обработка идет преимущественно на тех же вычислительных узлах, где данные и хранятся.
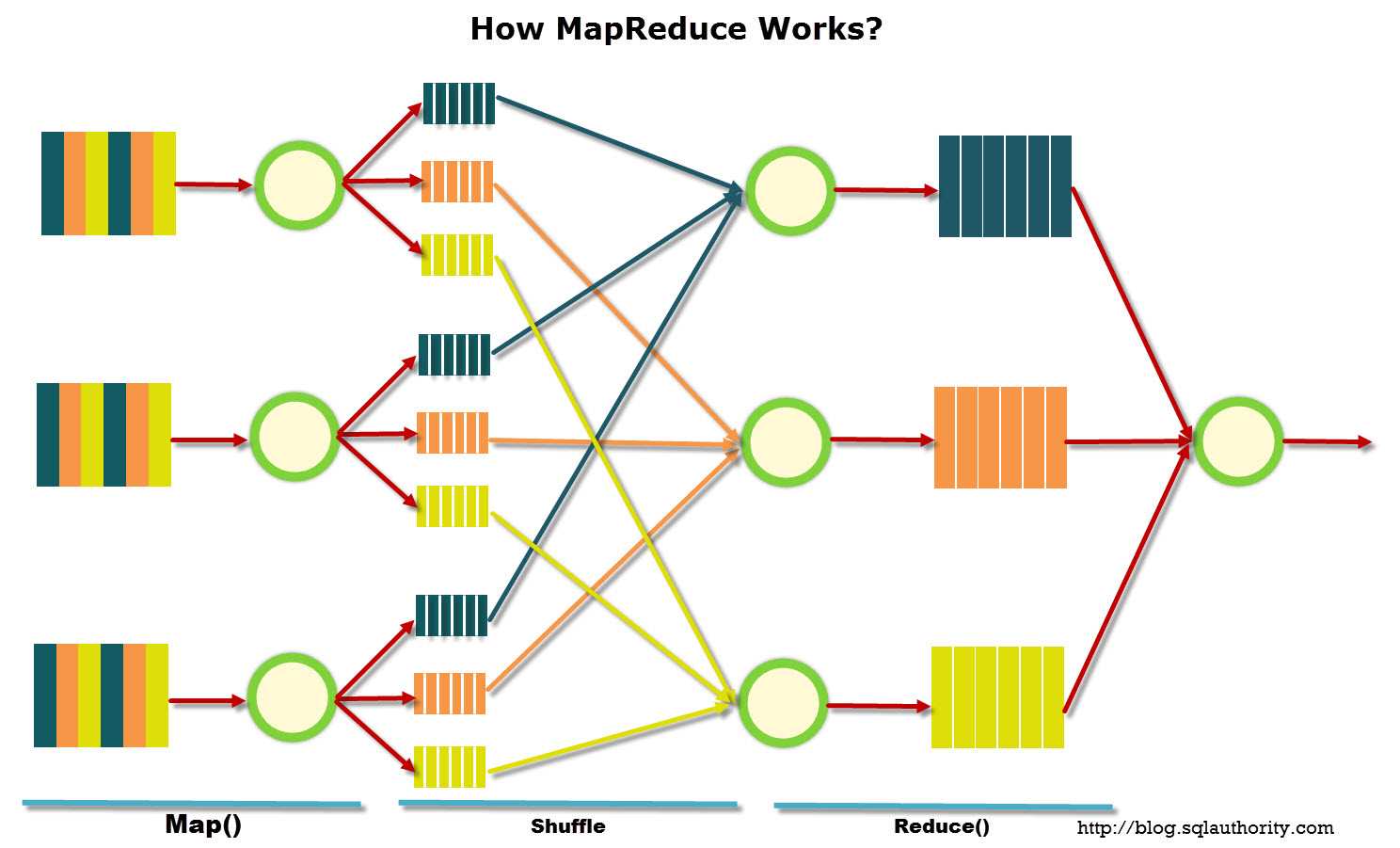
Этапы «сортировки» исходных данных в MapReduce
Распределенные вычисления требуют особой организации исходных данных. Часто для использования в больших массивах данных, вплоть до петабайт (десять в пятнадцатой степени байт) используется модель, предложенная компанией Google, которая называется MapReduce.
По возможности, все данные подчинены принципу локальности — чтобы избежать затрат ресурсов на трансфер биг даты. Обработка идет преимущественно на тех же вычислительных узлах, где данные и хранятся.Распределенные вычисления требуют особой организации исходных данных. Часто для использования в больших массивах данных, вплоть до петабайт (десять в пятнадцатой степени байт) используется модель, предложенная компанией Google, которая называется MapReduce.
Данный фреймворк включает в себя несколько этапов «сортировки» исходных данных. Сначала главный узел кластера, называемый , «просеивает» информацию, создавая так называемые пары ключ-значение. Эти пары он передает рабочим узлам кластера () и уже они сортируют данные, так сказать, по корзинам.
Визуально это можно себе представить так: система сортирует студентов по имени, составляя очереди, одна очередь для каждого имени. Далее идет сокращение объема данных, например, подсчет количества студентов в каждой очереди, с указанием частоты того или иного имени.
Данные, собираемые в массив, хранятся в специальных нереляционных СУБД с возможностью доступа посредством языка SQL. В таких системах управления базами данных проблема масштабируемости и доступности решается за счёт полного или частичного отказа от требований атомарности и согласованности данных.
Называются такие системы NoSQL. Они существуют с конца 1960-х годов, но само название «NoSQL» было придумано только в начале XXI века, с появлением концепции Web 2.0, когда объем информации резко возрос.
Одним из инструментов для реализации поисковых и контекстных запросов для ресурсов с высокой загруженностью стала разработка Apache Hadoop, бесплатный набор утилит, библиотек и фреймворк. Он используется, например, Facebook и Yahoo!, а также в других проектах распределенных вычислений, для применения на кластерах из сотен и тысяч узлов.
Первый дата-центр
Первый дата-центр был учрежден американским правительством в 1965 году и был предназначен для хранения миллионов отпечатков пальцев и записей об уплаченных налогах. Записи фиксировались на магнитных лентах, которые систематизировались и хранились в специальном помещении. Считается, что это было первым электронным хранилищем информации.
В 1989 году британский специалист по информатике Тим Бернерс-Ли изобрел всемирную компьютерную сеть, задавшись целью обеспечить обмен информацией посредством гипертекстовой системы. Тогда он даже представить не мог, какое влияние на мир окажет его изобретение, впоследствии получившее название «Интернет». После начала девяностых все больше устройств начало подключаться к глобальной сети, а значит, темпы генерирования данных стали расти еще активней.
В 1995 году был создан первый суперкомпьютер. Эта машина была способна за секунды выполнять работу, на которую у простого человека потребовались бы тысячи лет. А потом наступил 21 век.

Здесь мы вновь обратимся к 2005 году, когда Роджер Мугалус ввел термин «большие данные»
В этом же году компания Yahoo создала ныне открытую платформу Hadoop, цель которой состояла в индексировании всего Интернета. Сегодня Hadoop используется миллионами предприятий для получения и обработки колоссальных объемов данных.

За последние 10 лет социальные сети стремительно развивались, а объемы информации, создаваемой пользователями, ежедневно росли. Компании и правительства одно за другим начали реализацию проектов в сфере Big Data. Например, в 2009 году правительство Индии создало крупнейшую базу биометрических данных, в которой хранятся отпечатки пальцев и сканы радужных оболочек глаза всех граждан страны.
В 2010 году глава Google Эрик Шмидт выступил на калифорнийской конференции Techonomy, рассказав, что за последние семь лет компания накопила 5 эксабайт данных. Вряд ли он мог представить, что к 2017 году аналогичный объем информации будет вырабатываться ежедневно. При этом темпы роста и не думают замедляться.
Взгляд в прошлое позволил нам составить примерное представление о том, какие тенденции нас ждут в будущем. Если два десятилетия назад самыми успешными были предприятия, которые владеют информацией, то сегодня успех имеют те, кто умеют наилучшим образом интерпретировать и использовать имеющуюся информацию. Вполне логично можно ожидать, что в будущем успех будет зависеть от способности заставить большие данные содействовать в принятии верных стратегических решений.
Заключение
Наиболее очевидная область применения технологии Big Data — маркетинг, однако сфера применений данной технологии расширяется с каждым днем. Анализ больших данных это не всегда поиск оптимальных продаж и продвижения тех или иных сервисов и услуг.
Так, например, Google вложил крупную сумму средств на сбор и анализ данных с мобильных телефонов в рамках проекта по борьбе с малярией в Африке. Тем самым интернет-гигант помогал ученым вовремя обнаружить болезнь и остановить её распространение.
Другой большой источник нескончаемого потока данных — NASA. Эта организация держит руку на пульсе сразу большого числа проектов — от центра моделирования климата до сети телескопов и космических летательных аппаратов, которые постоянно присылают снимки в большом разрешении.
Одних только космических моделей, телеметрии, изображений и другой полезной информации, собранной в ходе планетарных миссий за последние 30 лет в архиве Planetary Data System хранится более 100 Тб.
Большие данные могут быть задействованы в любых социологических исследованиях и, что особенно важно — в информационных войнах. Не секрет, что подобная технология уже вовсю задействуется для формирования лояльной аудитории к политическим фигурам
Так, например, не секрет, что во время выборов президента США в 2016 году маркетологи Дональда Трампа использовали психолого-поведенческий анализ и персонифицированную рекламу, систематизируя интересы избирателей. В зависимости от их предпочтений им выдавались те или иные месседжи, которые подходили под их потребности, настроения, политические предпочтения и даже цвет кожи. В штабе Хиллари Клинтон опирались на классические статистические методы.
Результат говорит сам за себя — Трамп победил с большим отрывом, вложив в «раскрутку» в два раза меньше средств по сравнению с оппонентом.
Влияние на людей математической модели, просчитанной с помощью больших данных, невероятно велико и поднимает очень важный этический вопрос — где та грань, за которой личная информация перестает быть таковой и вправе ли кто-нибудь использовать подобные сведения ради выгоды. А может, проблема будет в большей или меньшей степени решена с помощью разработанного недавно протокола конфиденциального вычисления или MPC (). Этот протокол дает возможность обмениваться пользовательскими данными конфиденциально, т. е. вместо обмена реальной информацией между серверами ведется обмен «секретами» — исходные данные в них обработаны математическими функциями. Но это уже тема для отдельного обсуждения.
Напоследок рекомендуем посмотреть очень содержательную онлайн-лекцию на тему «Big Data в жизни современного человека» от заведующего учебно-научной лабораторией компьютерных средств обучения ТГУ Артем Фещенко: