
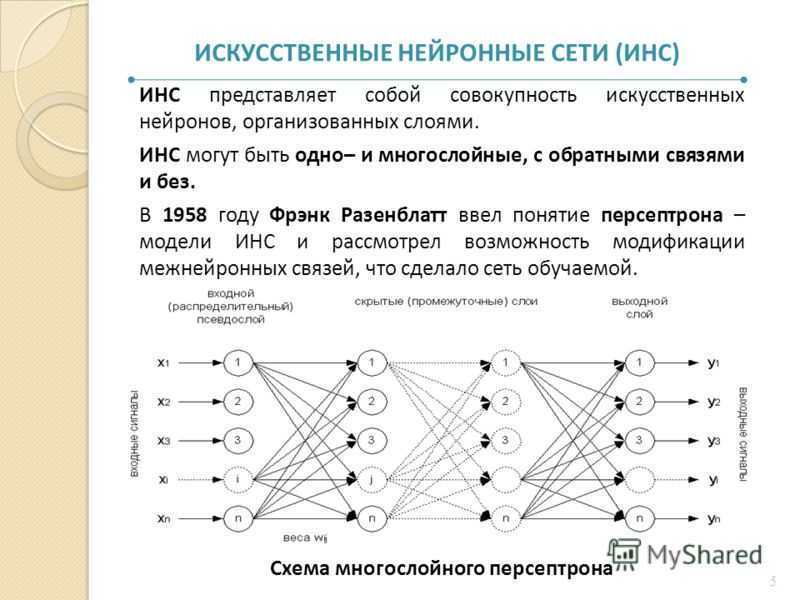
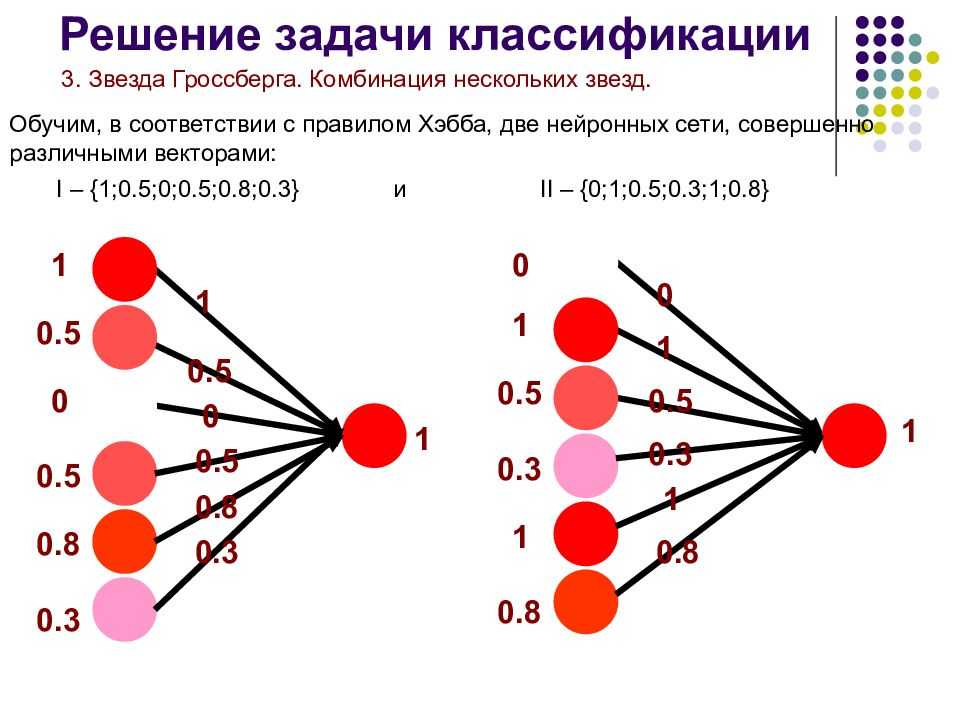
Искусственный нейрон
Теперь мы переходим к рассмотрению внутренней структуры искусственного нейрона и того, как он преобразует поступающий на его входы сигнал.
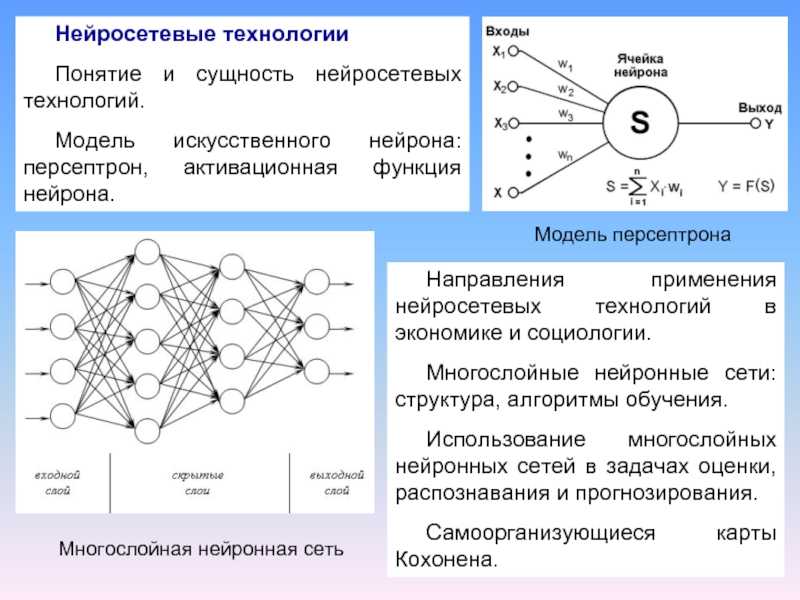
На рисунке ниже представлена полная модель искусственного нейрона.
Не пугайтесь, ничего сложного здесь нет. Давайте рассмотрим все подробно слева направо.
Входы, веса и сумматор
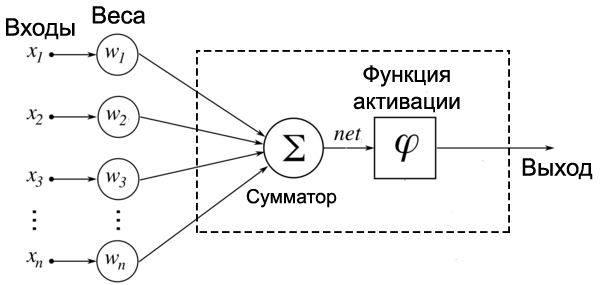
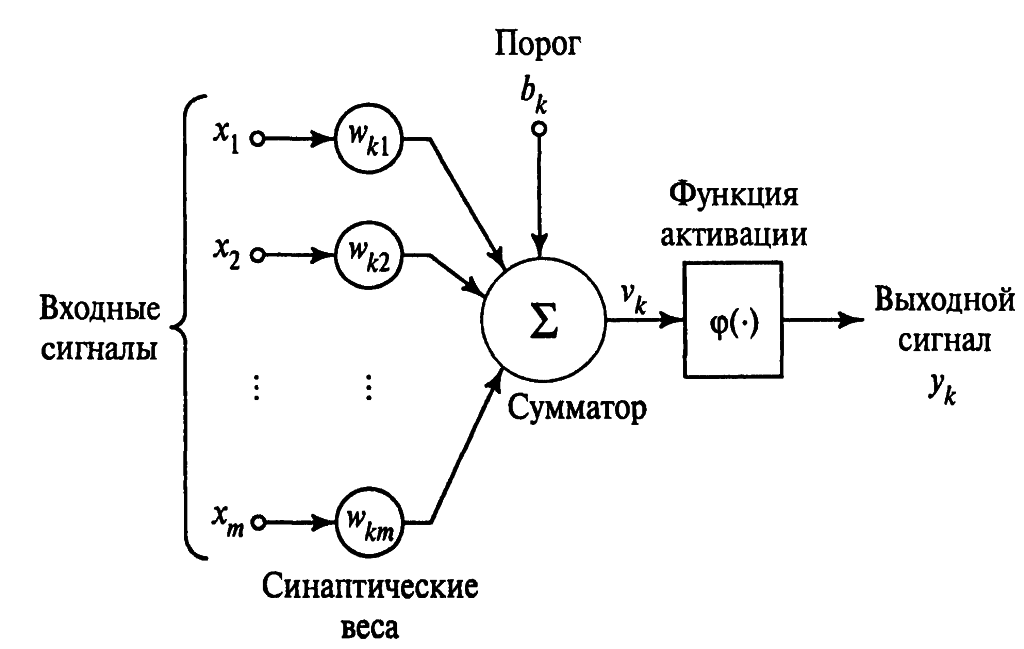
У каждого нейрона, в том числе и у искусственного, должны быть какие-то входы, через которые он принимает сигнал. Мы уже вводили понятие весов, на которые умножаются сигналы, проходящие по связи. На картинке выше веса изображены кружками.
Поступившие на входы сигналы умножаются на свои веса. Сигнал первого входа \( x_1 \) умножается на соответствующий этому входу вес \( w_1 \). В итоге получаем \( x_1w_1 \). И так до \( n \)-ого входа. В итоге на последнем входе получаем \( x_nw_n \).
Теперь все произведения передаются в сумматор. Уже исходя из его названия можно понять, что он делает. Он просто суммирует все входные сигналы, умноженные на соответствующие веса:
\
Результатом работы сумматора является число, называемое взвешенной суммой.
Взвешенная сумма (Weighted sum) (\( net \)) — сумма входных сигналов, умноженных на соответствующие им веса.
\
Роль сумматора очевидна – он агрегирует все входные сигналы (которых может быть много) в какое-то одно число – взвешенную сумму, которая характеризует поступивший на нейрон сигнал в целом. Еще взвешенную сумму можно представить как степень общего возбуждения нейрона.
Пример
Для понимания роли последнего компонента искусственного нейрона – функции активации – я приведу аналогию.
Давайте рассмотрим один искусственный нейрон. Его задача – решить, ехать ли отдыхать на море. Для этого на его входы мы подаем различные данные. Пусть у нашего нейрона будет 4 входа:
- Стоимость поездки
- Какая на море погода
- Текущая обстановка с работой
- Будет ли на пляже закусочная
Все эти параметры будем характеризовать 0 или 1. Соответственно, если погода на море хорошая, то на этот вход подаем 1. И так со всеми остальными параметрами.
Если у нейрона есть четыре входа, то должно быть и четыре весовых коэффициента. В нашем примере весовые коэффициенты можно представить как показатели важности каждого входа, влияющие на общее решение нейрона. Веса входов распределим следующим образом:
- 5
- 4
- 1
- 1
Нетрудно заметить, что очень большую роль играют факторы стоимости и погоды на море (первые два входа). Они же и будут играть решающую роль при принятии нейроном решения.
Пусть на входы нашего нейрона мы подаем следующие сигналы:
- 1
- 1
Умножаем веса входов на сигналы соответствующих входов:
- 5
- 1
Взвешенная сумма для такого набора входных сигналов равна 6:
\
Все классно, но что делать дальше? Как нейрон должен решить, ехать на море или нет? Очевидно, нам нужно как-то преобразовать нашу взвешенную сумму и получить ответ.
Вот на сцену выходит функция активации.
Простыми словами: что такое нейросеть
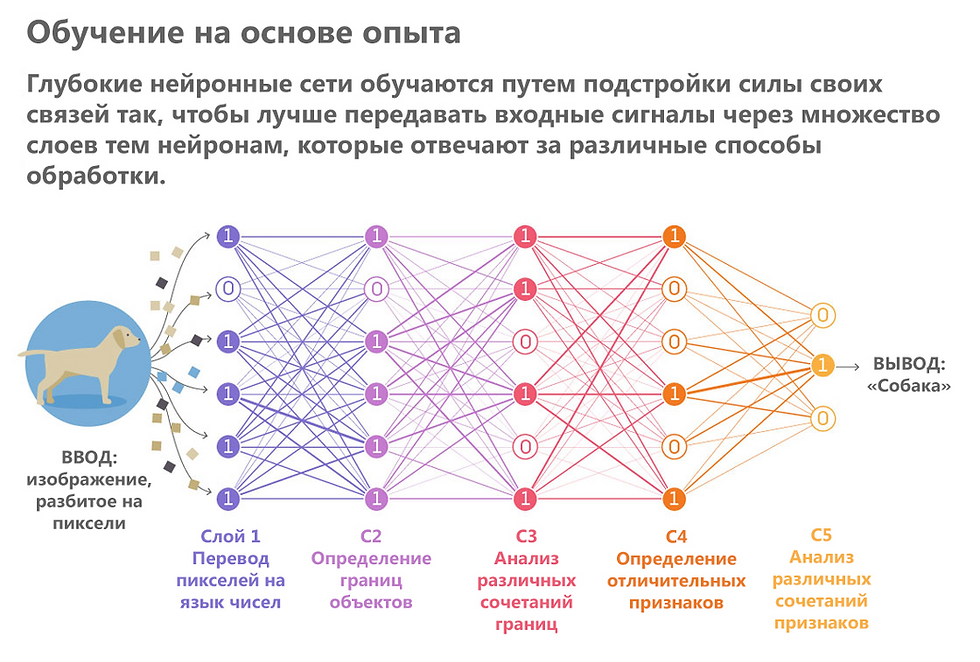
Представьте, что вам нужно написать программу, которая распознаёт котов по фото. Можно написать длинный список правил и алгоритмов по типу «если есть усы и шерсть, то это кот». Но всех условий учесть нельзя — скажем, если хозяйка одела кота в костюм Санта-Клауса или супергероя, алгоритм будет бессилен. В этом случае нам поможет нейронная сеть.
Нейросеть — это программа, которая умеет обучаться на основе данных и примеров. То есть она не работает по готовым правилам и алгоритмам, а пишет их сама во время обучения. Если показать ей миллион фотографий котов, она научится узнавать их в любых условиях, позах и костюмах.
Хитрость нейросети в том, что алгоритмы в ней устроены как нейроны в человеческом мозге — то есть они связаны между собой синапсами и могут передавать друг другу сигналы. Именно от силы этих сигналов и зависит обучение — например, в случае с котами нейросеть сформирует сильные связи между нейронами, распознающими морду и усы.
А чтобы нейронка ещё быстрее решала задачи, разработчики придумали располагать нейроны на разных слоях. Вот, например, как будут работать слои нейросети, если загрузить в неё, скажем, картинку с котом из Шрека:
- Входной слой — получает данные. Картинка раскладывается на пиксели, каждый из которых поступает на отдельный нейрон.
- Скрытые слои — творят магию. Именно в них происходит обработка данных. Нейросеть узнаёт кота, шляпу, траву и другие детали. Условно можно сказать, что чем больше слоёв в нейронке, тем она умнее.
- Выходной слой — выдаёт результат. Нейросеть собирает пазл воедино и отвечает: «Это же тот мем, где Кот в сапогах трогательно смотрит в камеру».
Упрощённо всю эту схему можно представить так (конечно, в реальности всё гораздо сложнее):
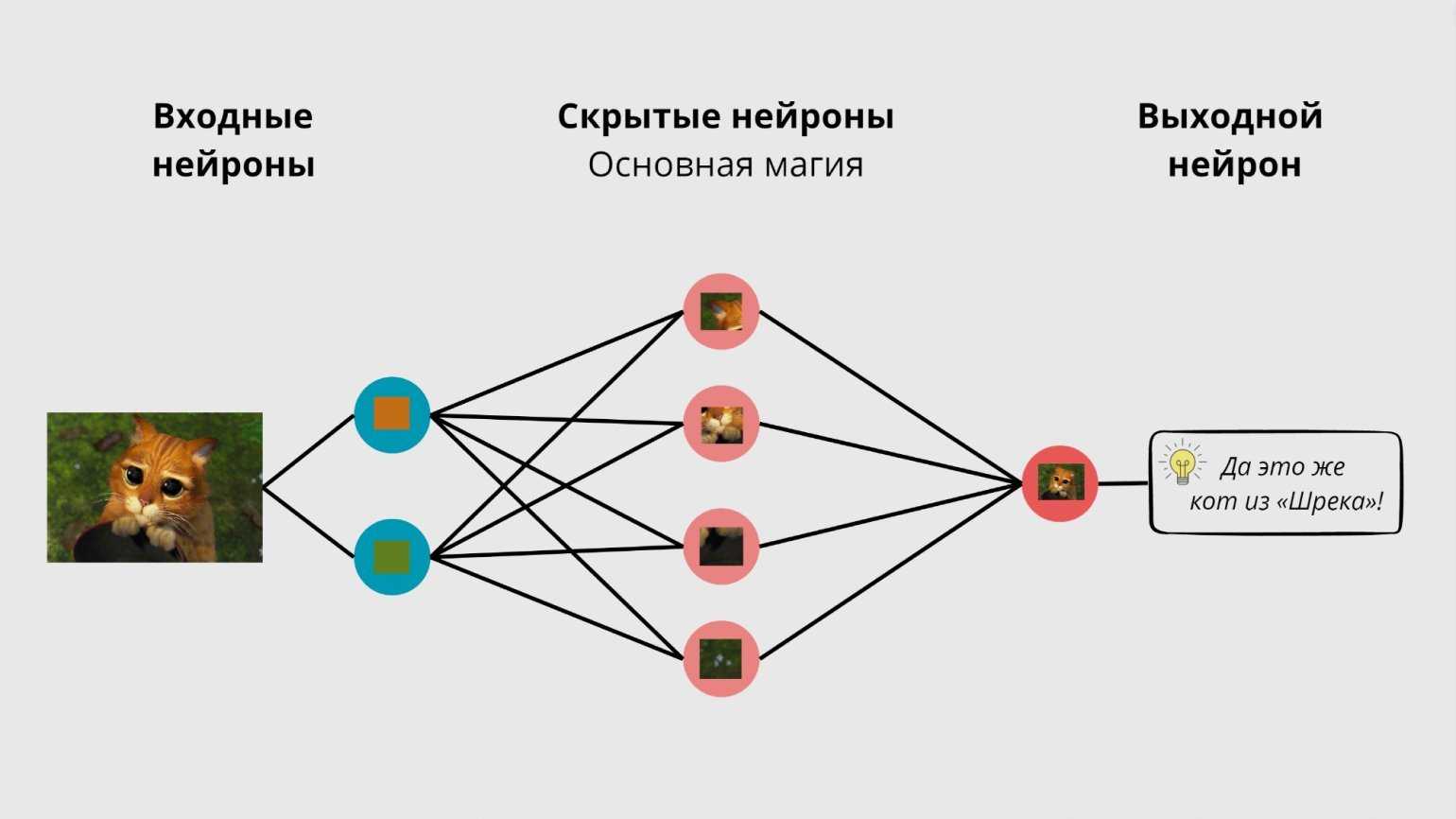
Изображение: Skillbox Media
Как видите, никакого мышления и сознания в нейросети нет — только алгоритмы и формулы. Единственное, что отличает её от других программ, — это способность обучаться и адаптироваться к новым задачам. О том, как это работает, поговорим чуть позже.

Будущее нейросетей: что нас ждет?
Нейросети уже сегодня на переднем крае технологического развития и являются одной из наиболее перспективных областей для дальнейшего исследования и развития.
Вот несколько трендов, которые могут определить будущее нейросетей:
- Более сложные архитектуры нейросетей: одним из ключевых направлений в развитии нейросетей является создание более сложных архитектур, способных решать более сложные задачи. Например, сегодня уже есть нейросети, способные с помощью генеративной моделирования создавать реалистичные изображения и видео.
- Улучшение интерпретируемости: одной из главных проблем, с которыми сталкиваются нейросети, является их сложность и непрозрачность. В будущем, исследователи будут продолжать работу над улучшением интерпретируемости нейросетей, чтобы их решения стали более понятными и прозрачными.
- Развитие обучения с подкреплением: сегодня обучение с подкреплением используется в ряде областей, от создания игр до управления роботами. В будущем, нейросети, использующие обучение с подкреплением, могут быть использованы в более сложных задачах, например, в разработке систем управления транспортом или управлении сложными производственными процессами.
- Использование в различных областях: нейросети могут быть использованы в различных областях, включая медицину, финансы, образование, рекламу и многое другое. В будущем, мы можем ожидать, что нейросети будут использоваться в более широком спектре задач и областей.
- Улучшение производительности: будут созданы быстрые и эффективные нейросети. Если закон Мура (удвоение
мощности компьютеровколичества транзисторов на квадратный дюйм схем каждые 2 года) будет актуален, то увеличение количества параметров моделей не за горами. А значит, еще много сюрпризов от нейросетей.
 Как вывести сайт в ТОП Яндекса и зарабатывать там, где ищут ответы. Бронируй место!
Как вывести сайт в ТОП Яндекса и зарабатывать там, где ищут ответы. Бронируй место!
На странице может содержаться реклама. Информация о рекламодателях по ссылкам на странице.
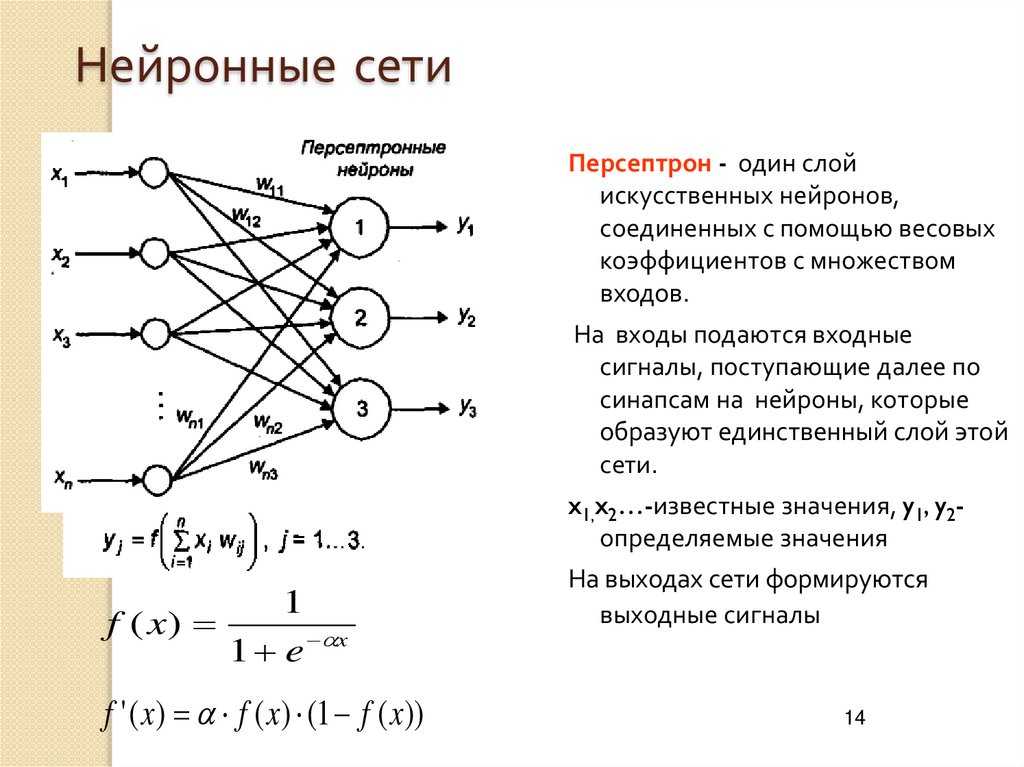
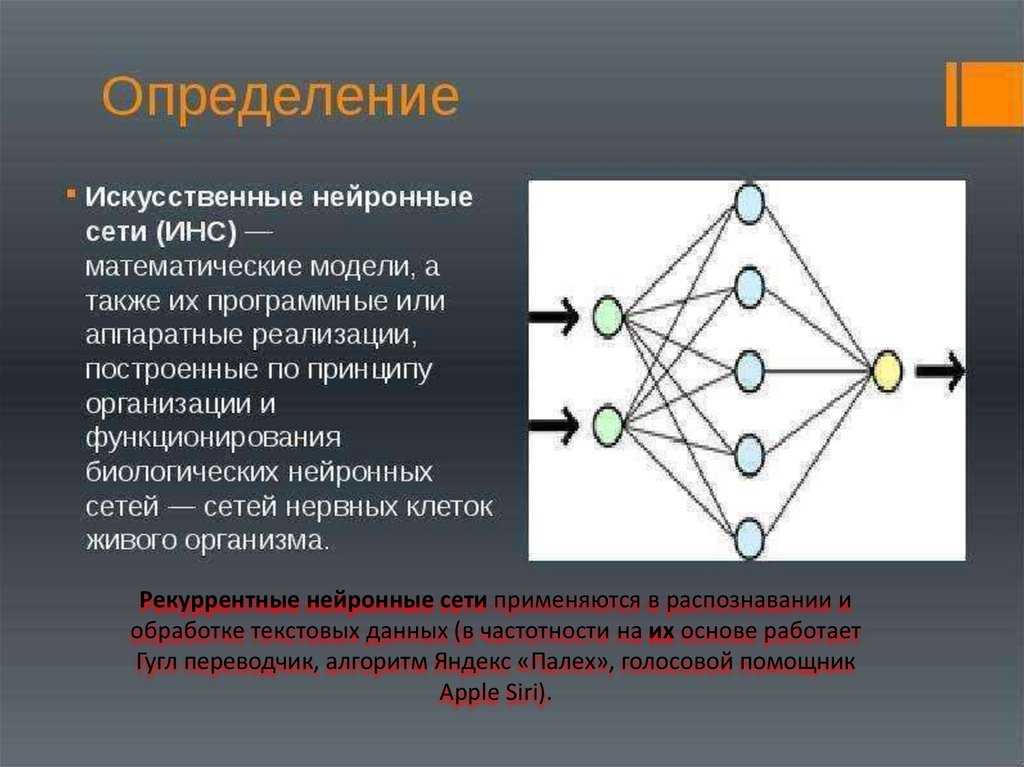
Что такое нейросети?
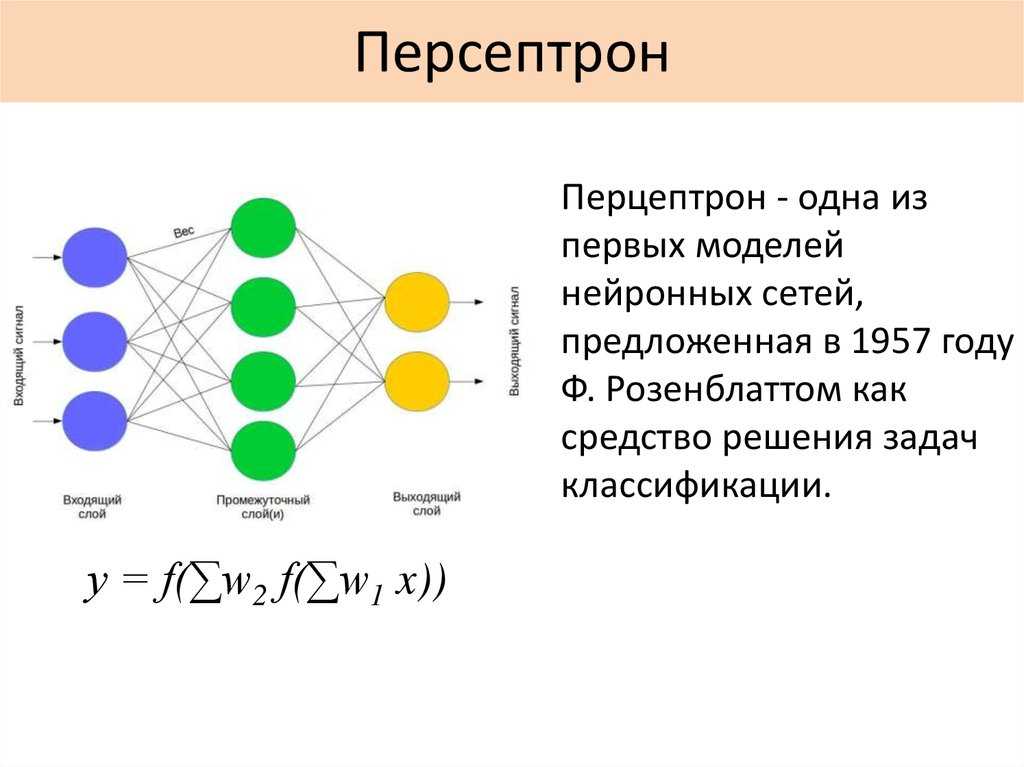
Нейросети — математические модели и их программное воплощение, основанные на строении человеческой нервной системы. Самую простую нейронную сеть, перцептрон (модель восприятия информации мозгом), вы сможете легко самостоятельно написать и запустить на своем компьютере, не используя сторонние мощности и дополнительные устройства.
Пройдите наш тест и узнайте, какой контент подготовил искусственный интеллект, а какой — реальный человек.
Чтобы лучше понять, что это такое, попробуем сначала разобраться, как работают биологические нейронные сети — те, что находятся внутри нашего организма. Именно они стали прообразом для машинных нейронных сетей.
Биологические нейронные сети. Нервная система живого существа состоит из нейронов — клеток, которые накапливают и передают информацию в виде электрических и химических импульсов. У нейронов есть аксон — основная часть клетки, и дендрит — длинный отросток на ее конце, который может достигать сантиметра в длину. Дендриты передают информацию с одной клетки на другую и работают как «провода» для нервных импульсов. С помощью специальных шипов они цепляются за другие нейроны, и так сигналы передаются по всей нервной системе.
25 месяцев
Data Scientist с нуля до PRO
Создавайте ML-модели и работайте с нейронными сетями

Data Scientist с нуля до PRO
В качестве примера можно привести любое осознанное действие. Например, человек решает поднять руку: импульс сначала появляется в его мозгу, потом через сеть нейронов информация передается от одной клетки к другой. По пути она преобразуется и в конечном итоге достигает клеток в руке. Рука поднимается. Так работает большинство процессов в организме — тех, которые управляются мозгом.
Но главная особенность нейронных сетей — способность обучаться. И именно она легла в основу машинных нейросетей.
Первые машинные нейросети. В сороковых годах прошлого века люди впервые попытались описать сеть нейронов математически. Затем, в пятидесятых, — воссоздать ее модель с помощью кода. Получилась та самая структура, которую назвали перцептрон. На графиках и иллюстрациях ее обычно рисуют как набор кругов и прямых, их соединяющих — это и есть нейроны, образующие сетку.
Перцептрон был проще современных нейросетей. Он имел всего один слой и три типа элементов: первый тип принимал информацию, второй обрабатывал и создавал ассоциативные связи, третий выдавал результат.
Но даже элементарная структура уже могла обучаться и более-менее точно решать простые задачи. Например, перцептрон мог ответить, есть ли на картинке предмет, который его научили распознавать. Он был способен отвечать только на вопросы, где есть два варианта ответов: «да» и «нет».
После этого развитие нейросетей замедлилось. Существующих на тот момент технологий было недостаточно, чтобы создать мощную систему. Наработки шли неторопливо, но чем больше развивалась компьютерная отрасль, тем больше интереса вызывал концепт.
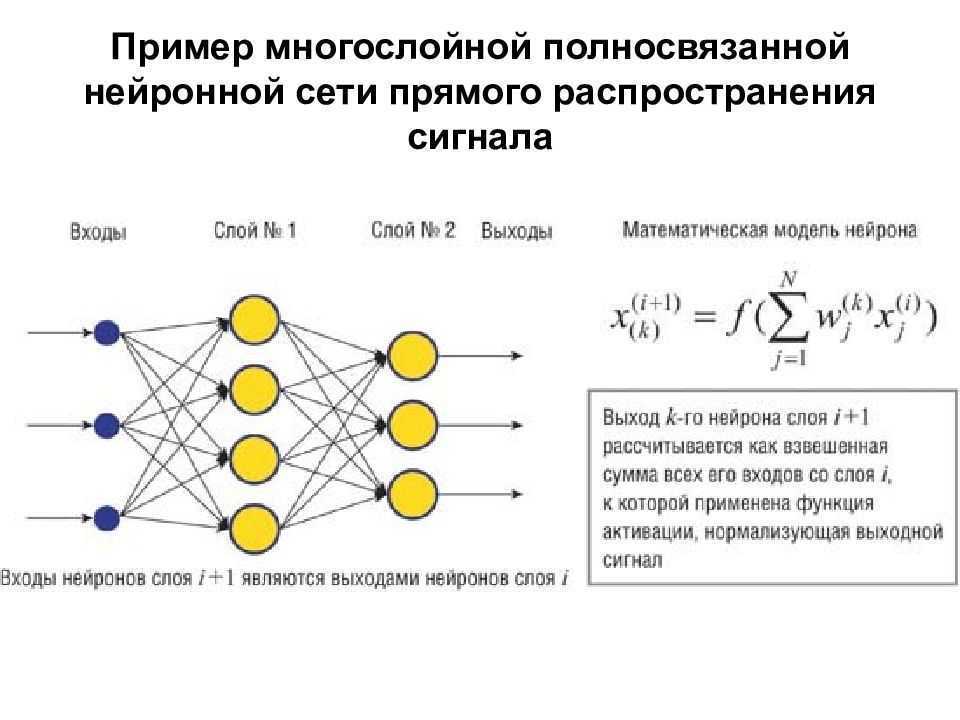
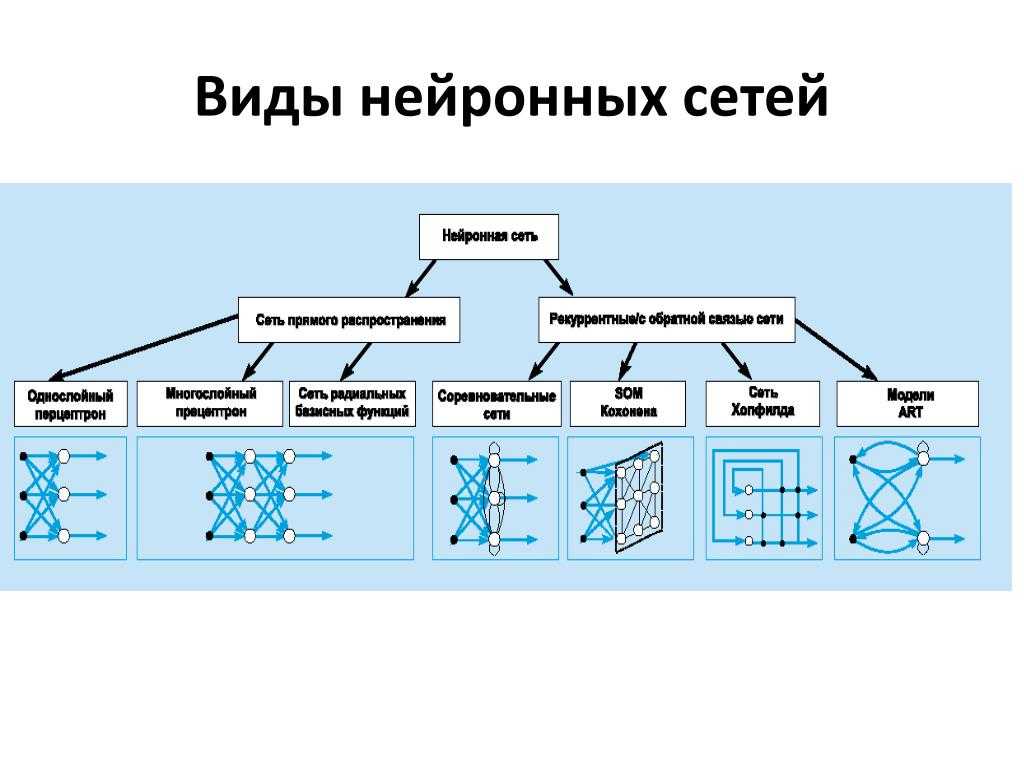
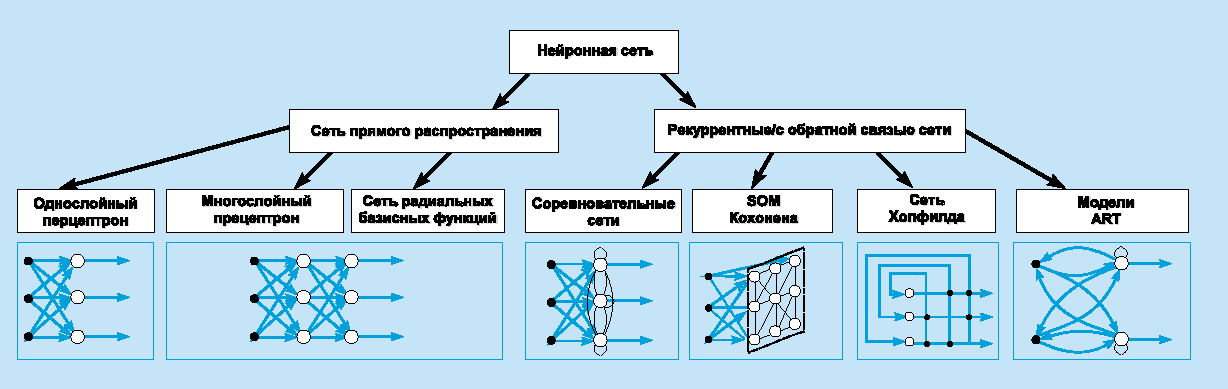
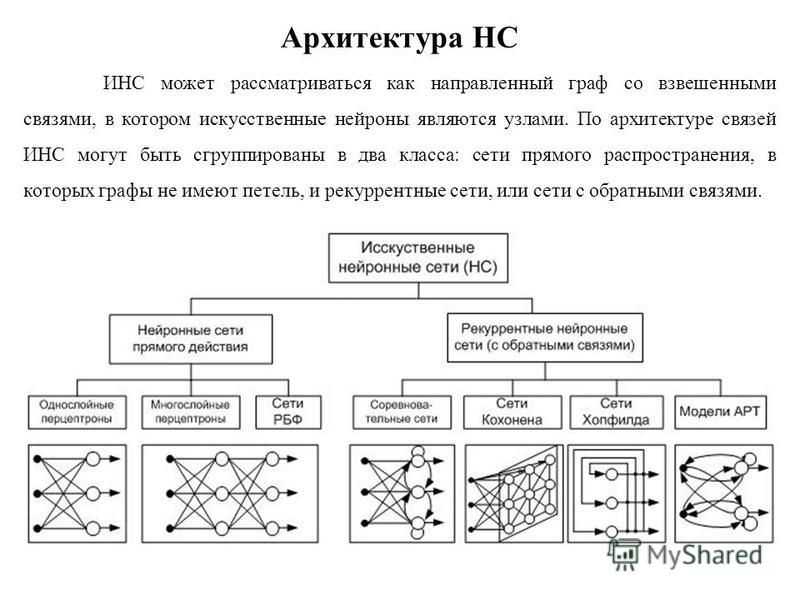
Современные нейронные сети. Когда компьютеры развились до современных мощностей, концепция нейронной сети снова стала привлекательной. К тому моменту ученые успели описать много алгоритмов, которые помогали распространять информацию по нейронам, и предложили несколько структур. Это были как однослойные, так и многослойные сети, однонаправленные и рекуррентные — подробнее мы расскажем о классификации далее.
Чем более продвинутыми становились компьютеры, тем больше сложных и интересных задач могли реализовать нейронные сети. Мощность системы играет важную роль, т.к. каждый нейрон постоянно выполняет ресурсоемкие вычисления. Чтобы решить сложную задачу, обычно нужно много нейронов, их масштабная структура и множество математических функций. Понятно, что для этого понадобится очень сильный компьютер.
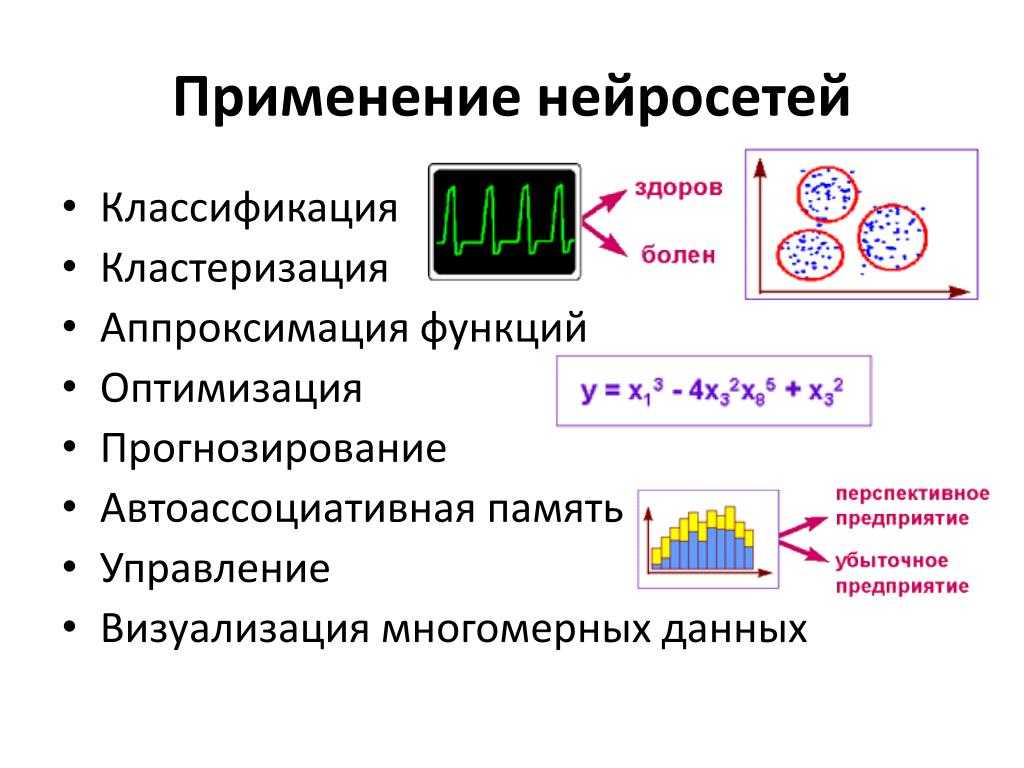
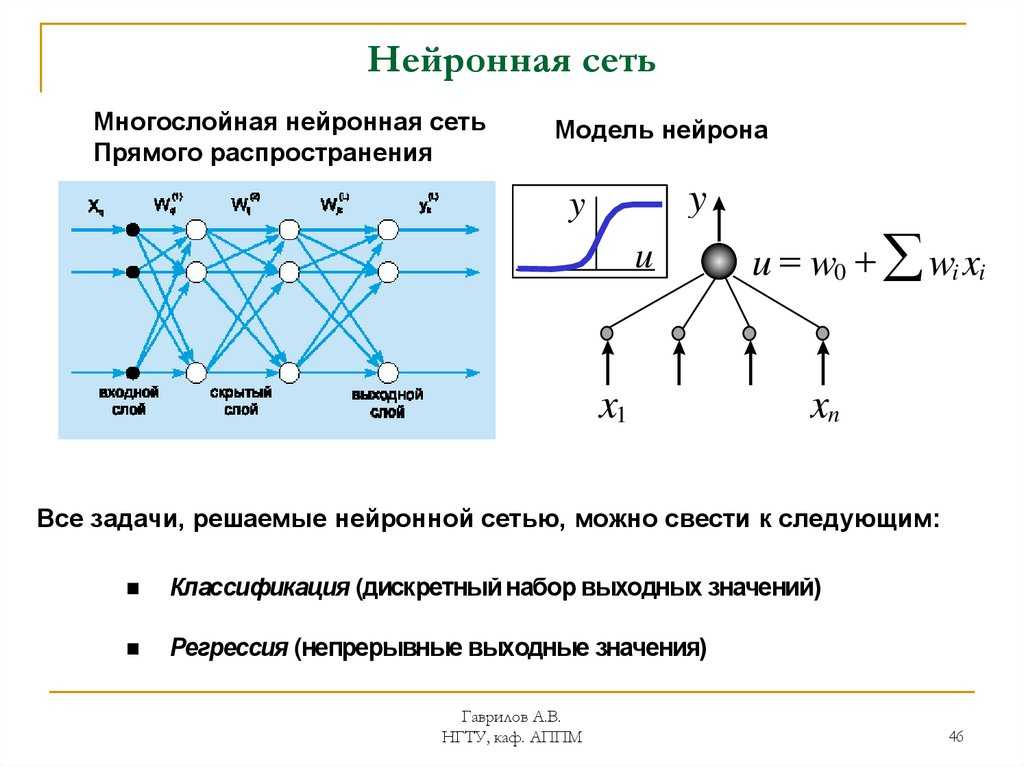
Типы задач, которые решают нейронные сети
Выделяют несколько базовых типов задач, для решения которых могут использоваться нейросети.
- Классификация. Для распознавания лиц, эмоций, типов объектов: например, квадратов, кругов, треугольников. Также для распознавания образов, то есть выбора конкретного объекта из предложенного множества: например, выбор квадрата среди треугольников.
- Регрессия. Для определения возраста по фотографии, составления прогноза биржевых курсов, оценки стоимости имущества и других задач, требующих получения в результате обработки конкретного числа.
- Прогнозирования временных рядов. Для составления долгосрочных прогнозов на основе динамического временного ряда значений. Например, нейросети применяются для предсказания цен, физических явлений, объема потребления и других показателей. По сути, даже работу автопилота Tesla можно отнести к процессу прогнозирования временных рядов.
- Кластеризация. Для изучения и сортировки большого объема неразмеченных данных в условиях, когда неизвестно количество классов на выходе, то есть для объединения данных по признакам. Например, кластеризация применяется для выявления классов картинок и сегментации клиентов.
- Генерация. Для автоматизированного создания контента или его трансформации. Генерация с помощью нейросетей применяется для создания уникальных текстов, аудиофайлов, видео, раскрашивания черно-белых фильмов и даже изменения окружающей среды на фото.
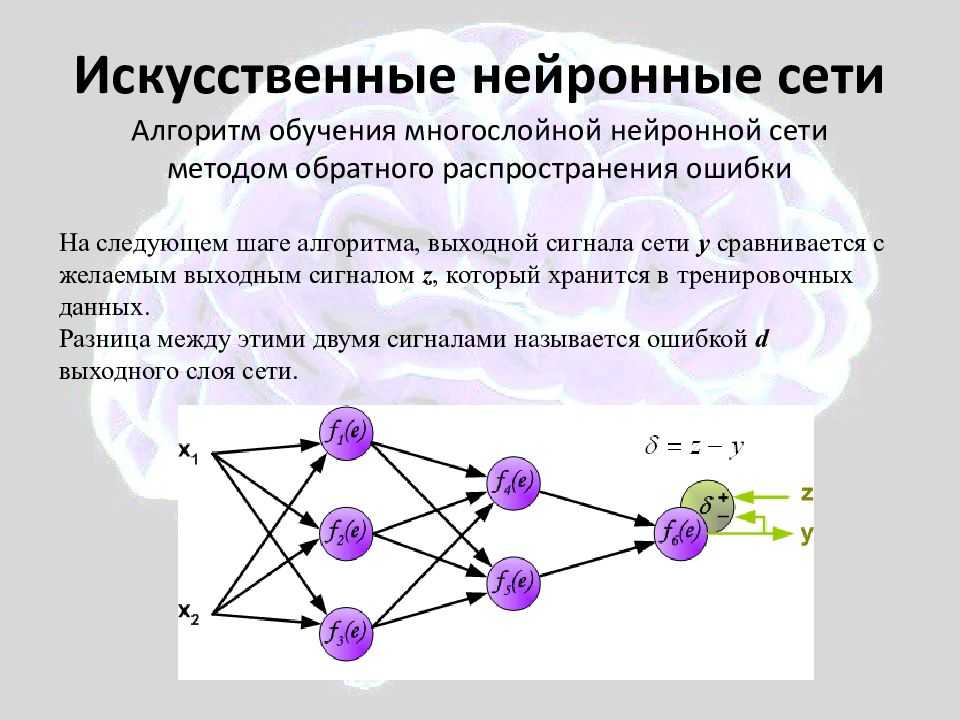
Математическая модель нейрона Маккаллока — Питтса разработана по аналогии с биологическими нервными клетками и выглядит следующим образом:
Где:
- X — входные данные — сигналы, поступающие к нейрону;
- W — вес — эквивалент синаптической связи, представленный в виде действительного числа, на которое умножается значение входного сигнала для определения степени взаимосвязи отдельных нейронов;
- H — тело нейрона — показатель накопленной взвешенной суммы, полученной в результате умножения значений входящих сигналов на вес;
- Y — выход нейронной сети — функция, получаемая в результате обработки входных сигналов.
Для определения выходных значений нейрона используются функции активации разного вида, каждая из которых влияет на работу нейронных сетей и отличается принципом оценки или преобразования данных.Так:
- Функция Хевисайда преобразовывает значения при их накоплении выше установленного порога. Например, значение +100 преобразовывается в 1, а -100 — в 0.
- Пороговая функция. Применяется для отображения состояния нейрона: его возбудимости или спокойствия. Может отображать только два значения: 0% и 100%.
- Синоидальные функции применяются для сглаживания значений.
Функция ReLU отсекает только отрицательные значения. Например, значение -100 преобразовывается в 0, а +50 остается неизменным.
Функция ReLu производит простые математические операции, поэтому помогает снизить нагрузку на вычислительные мощности при глубоком обучении.
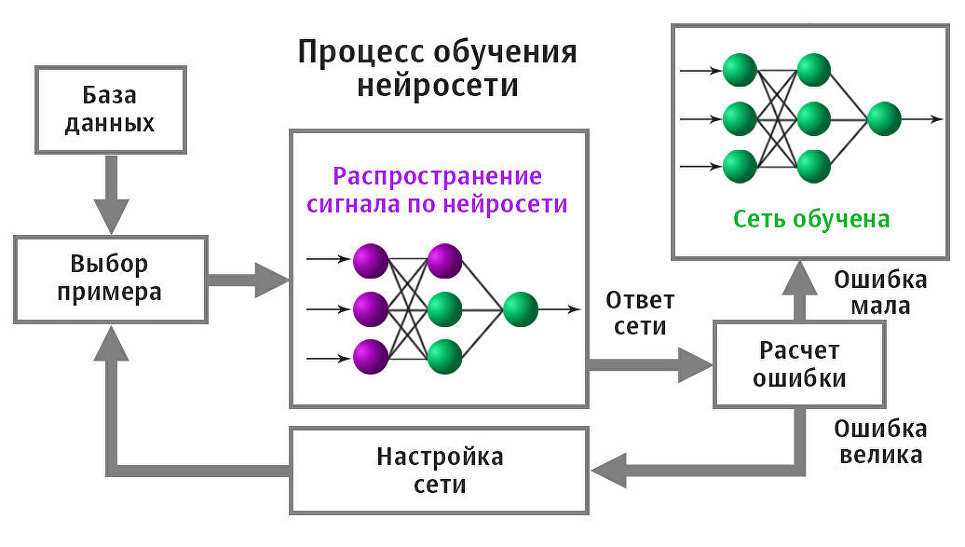
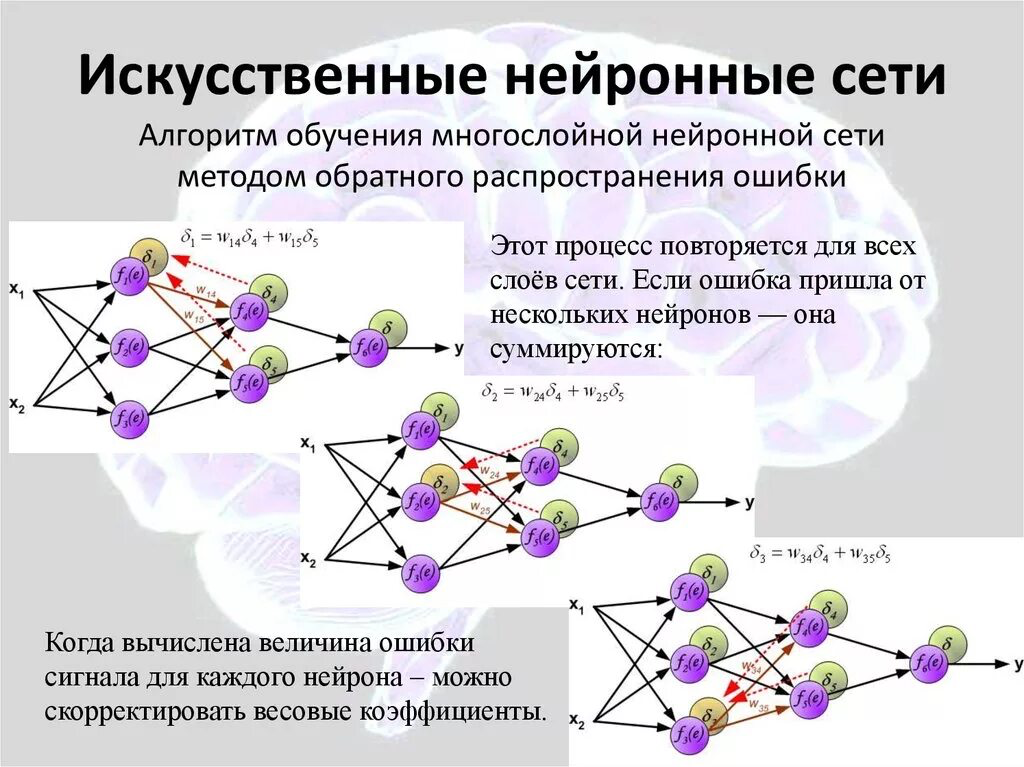
Нейросети, в отличие от других алгоритмов ИИ, не программируются на выполнение конкретных задач, а просто настраиваются на изучение информации.Стратегия обучения нейронных сетей базируется на трех методах:
- Контролируемое обучение. Классическая модель обучения, в которой используется набор размеченных данных, показывающий алгоритму что и как должно быть. Обучение продолжается до полного перестраивания алгоритма под решение конкретных задач и получения нужного результата.
- Обучение без контроля. Стратегия обучения, применяемая в ситуациях, когда нет размеченных наборов данных. В этой модели нейронная сеть выполняет анализ, а после получает внутренний отчет о точности расчета. Если значение недостаточно, нейронная сеть усиливается и повторяет операцию.
- Усиленное обучение. Модель, при которой нейронная сеть усиливается при получении положительного результата и наказывается за неправильные расчеты.
Мы предлагаем готовые решения для работы с искусственным интеллектом, машинным обучением и нейронными сетями. Клиентам доступны платформа для совместной ML-разработки с ускорением до +1700 GPU Tesla v100 и A100 ML Space, инструменты для обработки языка ruGPT-3 & family и другие сервисы.
Нейроны как логические элементы
К анализу поведения нейронов можно подойти с позиций математической логики.
Для этого сконцентрируемся на одном классе задачи xor, например на крестиках.
Запишем логическое условие которому удовлетворяют все объекты этого класса.
В примере выше: «любой крестик лежит по вектору плоскости A
и по вектору плоскости B«.
Это кратко можно выразить формулой A & B.
Выходной нейрон «C» реализует такое логическое «И».
Действительно, его плоскость прижата к правому нижнему углу квадрата в пространстве признаков с координатами
(1,1).
Поэтому для входов (поставляемых нейронами «A» и «B«)
близких к единице,
на выходе этого нейрона будет
1 (точнее его значение больше 0.5).
Поэтому, как и положено, 1 & 1 = 1.
Если хотя бы один из входов отличен от 1, то и выход будет нулевым
(меньшим 0.5). Это справедливо и в пространстве произвольной
размерности, где гиперплоскость нейрона, обеспечивающего логическое «И» прижата
к углу гиперкуба с координатами (1,1,…,1) (отсекает его от остального гиперкуба).
Если плоскость сместить в угол (0,0), сохранив направление нормали к углу (1,1),
то такой нейрон будет логическим «ИЛИ». Его функция y=S(x1,x2)
даёт S(0,0)=0 и в остальных случаях 1 (ниже первый рисунок):
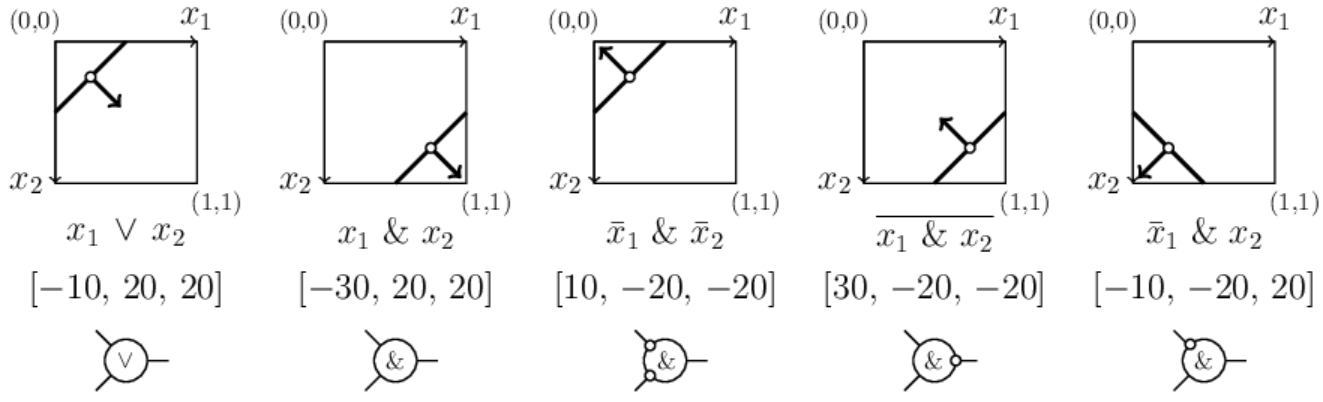
В общем случае, плоскость нейрона, реализующего логическое «ИЛИ» отсекает угол (0,0,…,0)
n-мерного куба, а вектор
его нормали направлен в сторону большего объём гиперкуба.
В отличии от этого, стандартное логическое «И» (второй рисунок) имеет вектор нормали в сторону меньшего объёма.
Логическое «И» для нейрона с n входами
описывается следующей функцией:
y = S( w·(x1+…+xn+α-n) ), y = x1 & x2 & … & xn,
где параметр α — параметр, лежащий в диапазоне 0<α<1.
Чем он ближе к нулю, тем сильнее
плоскость прижата к углу с координатами (1,1,…,1).
Действительно, когда α=0 и x1=…=xn=1,
имеем x1+…+xn-n=0.
Чтобы этот нейрон обеспечивал логическое И, он должен давать отрицательное расстояние к
«ближайшему» углу гиперкуба у которого одна координата равна нулю: (1,…,1,0,1,…,1).
Это даёт ограничение α<1.
Общий множитель w
характеризует длину нормали (чем он больше, тем более уверен в себе нейрон).
S(d) приведена в начале документа.
Аналогично записывается функция логического «ИЛИ» (0<α<1)
y = S( w·(x1+…+xn-α) ), y = x1 ∨ x2 ∨ … ∨ xn.
Ещё одна логическая функция отрицания реализуется при помощи вычитания.
Обозначим её чертой над именем переменной. Тогда x = 1-x
и, как обычно, =1, 1=0.
Если один из входов нейронов имеет отрицание, то его функция выхода имеет вид:
y = S( w·(-x1+…+xn+α-n+1) ), y = x1 & x2 & … & xn.
Таким образом, одна из компонент вектора нормали меняет свой знак и плоскость нейрона сдвигается.
Выше на третьем и четвёртом рисунках приведены различные отрицания перменных.
Стоит в этих терминах получить логическое ИЛИ из логического И при помощи правила де-Моргана:
!(x1 & x2) = x1 ∨ x2,
где восклицательный
знак — ещё один способ обозначения логического отрицания.
Полезность нейрона
В случае,
если гиперплоскость нейрона не пересекает единичный гиперкуб в котором
находятся признаки (или значения выходов предыдущих нейронов), то
от такого нейрона обычно мало пользы.
Он не разделяет на две части входные данные (которые всегда принадлежат
интервалу .
Такой нейрон будет называться бесполезным.
Необходимо стремиться к тому, чтобы все нейроны сети были полезными.
Иногда бесполезность появляется и для плоскости, пересекающей гиперкуб,
если объекты любых классов оказываются с одной стороны этой плоскости.
Перед началом обучения параметры нейронов полагают равными случайным значениям.
При этом нейрон может сразу оказаться бесполезным.
Чтобы этого не произошло, можно использовать следующий алгоритм инициализации:
Компоненты вектора ω задаём случайным образом, например в диапазоне ,
где w ~ 1 — 10.
Затем, внутри единичного гиперкуба (или в некоторой его центральной части), выбираем
случайную точку
x={x01,…,x0n}.
Параметр сдвига задаём следующим образом:
w = —ω·x = -(w1x01 + … + wnx0n).
В результате гиперплоскость будет гарантированно проходить через гиперкуб.
Параметр сдвига стоит контролировать и в процессе обучения,
так чтобы нейрон был всё время полезным.
Здесь возможны два способа — геометрический и эмпирический.
В эмпирическом вычисляется среднее значение выхода каждого нейрона по обучающим объектам.
Если после прохождения через сеть всех обучающих примеров, средние значения <y>
некоторых нейронов близки к нулю или единице, то они считаются бесполезными.
В этом случае их можно «встряхнуть» случайным образом (возможно с сохранением вектора ω,
изменяя только параметр сдвига w).
На всех примерах в этом документе нейроны в сетях разукрашены в соответствии со значением
их <y>. Если <y> = 0.5, то нейрон белый,
если <y> = 0 — синий, а если
<y> = 1 — красный.
Насыщенный синий или красный цвета означают бесполезность нейрона.
В первых двух примерах, единственный нейрон получился очень полезным (белым), так как объекты
классов равновероятно находились справа и слева от линии (разделяющей гиперплоскости).
Кроме среднего значения выхода, важную роль играет волатильность нейрона σy,
равная среднеквадратичным отклонениям его выхода от среднего значения
<y>.
Чем волатильность меньше, тем
менее полезен нейрон. Действительно, в этом случае, не зависимо от значений входов,
он принимает одно и то же значение на выходе. Поэтому, без изменения выходных значений сети,
такой нейрон можно выбросить, сдвинув соответствующим образом параметры
нейронов, для которых бесполезный нейрон является входным.
Глубокое обучение: принципы работы и результаты использования
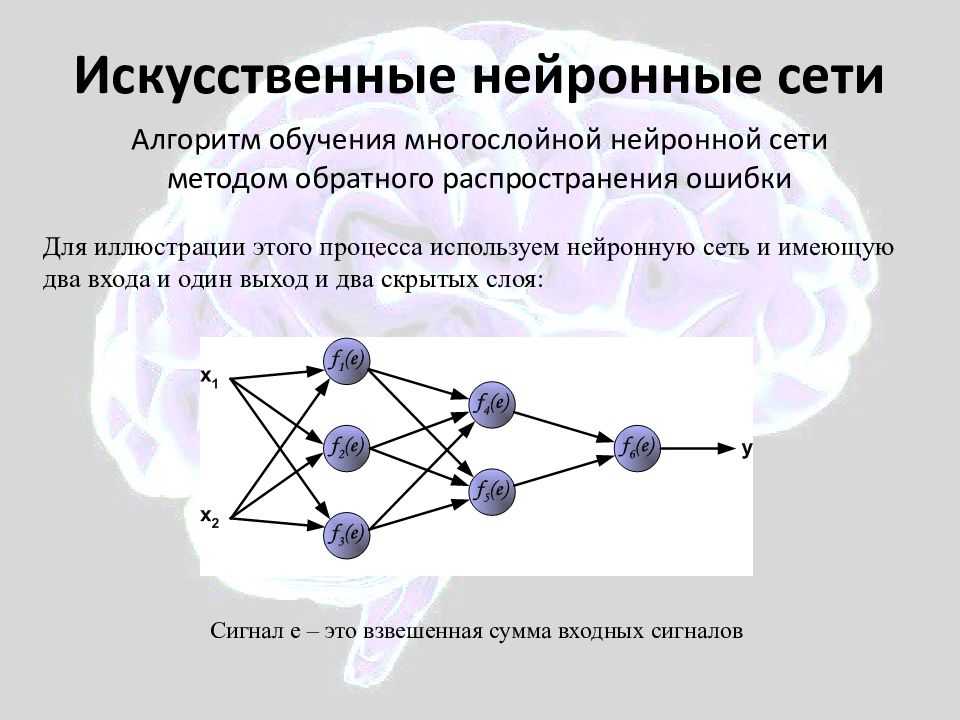
К глубокому обучению относят класс ML-моделей, основанных на обучении представлениями (feature/representation learning), а не на специализированных алгоритмах под конкретные задачи. В DL многослойные нейронные сети играют роль многоуровневой системы нелинейных фильтров для извлечения признаков. Для DL-моделей характерно иерархическое сочетание нескольких алгоритмов обучения: с учителем, без учителя, с подкреплением. Архитектура нейросети и состав ее нелинейных слоёв зависит от решаемой задачи. При этом используются скрытые переменные, организованные послойно, например, узлы в глубокой сети доверия и глубокой ограниченной машине Больцмана. При этом, независимо от архитектурных особенностей и прикладного назначения, для всей DL-сетей характерно предварительное обучение на большом объеме общих данных с последующей подстройкой на датасетах, специфичных для конкретного применения .
Например, одна из наиболее известных реализаций DL-моделей, нейронная сеть BERT, о которой я рассказывал здесь, предварительно обучена на статьях из Википедии, чтобы затем использоваться в распознавании текстов. По аналогичному принципу работает нейросеть XLNet, также применяемая в задачах обработки естественного языка для анализа и генерации текстов, извлечения данных, информационного поиска, синтеза речи, машинного перевода, автоматического реферирования, аннотирования, упрощения текстовой информации и прочих NLP-проблем . Другая глубокая нейросеть, CQM (Calibrated Quantum Mesh), также показывает отличные результаты (более 95%) в понимании естественного языка, извлекающая смысл слова на основе вероятностного анализа его окружения (контекста) без использования заранее заданных ключевых слов . На рисунке 5 показано использование предварительно подготовленной модели в качестве объектов в отдельной нисходящей DL-сети при трансферном обучении в NLP-задачах .
Рис. 5. Схема трансферного обучения в DL-сетях
Среди других DL-моделей стоит упомянуть капсульные сети, которые, в отличие от сверточных сетей, обрабатывают визуальные образы с учетом пространственной иерархии между простыми и сложными объектами, что повышает точность классификации и снижает объем данных для обучения . Также отметим глубокое обучение с подкреплением (DRL, Deep Reinforcement Learning), работающее по принципу взаимодействия нейросети с окружающей средой посредством наблюдений, действий, штрафов и вознаграждений . DRL считается наиболее универсальным из всех ML-методов, поэтому его можно использовать в большинстве бизнес-приложений. В частности, именно к DRL-моделям относится нейросеть AlphaGo, которая в 2015 году впервые победила человека в соревнованиях по древней китайской игре го, а в 2017 – обыграла сильнейшего профессионального игрока в мире .
А для распознавания образов, получения фотореалистичных изображений, улучшения качества визуальной информации и обеспечения кибербезопасности активно используются GAN-подобные сети. GAN-сеть представляет собой комбинацию двух конкурирующих нейросетей, одна из которых (G, генератор) генерирует образцы,а другая (D, Дискриминатор) старается отличить правильные («подлинные») образцы от неправильных, обрабатывая все данные. Со временем каждая сеть улучшается, благодаря чему качество обработки данных существенно возрастает, т.к. в процесс обучения уже заложена функция обработки помех. Эту систему DL-обучения без учителя впервые описал Ян Гудфеллоу из компании Google в 2014 году, а сама идея состязательного обучения была выдвинута в 2013 году учеными Li, Gauci и Gross. Сегодня GAN-сети активно используются в видеоиндустрии и дизайне (для подготовки кадров фильмов или мультипликации, сцен компьютерных игр, создания фотореалистичных изображений), а также в космической промышленности и астрономии (для улучшения снимков, полученных из астрономических наблюдений) . Таким образом, GAN-сети отлично подходят для широкого спектра задач обучения без учителя, где помеченные данные не существуют или процесс их подготовки слишком дорог, например, создание 3D-образа удаленного объекта на основе его фрагментарных изображений. Благодаря состязательному подходу, этот ML-метод оказывается быстрее аналогичных DL-моделей, т.к. используются сразу две сети с противоположными локальными целями, направленными на общий глобальный результат .
Вместо заключения
Как видите, возможности нейросетей ограничиваются только фантазией человека. Роботы пишут музыку, создают сайты, генерируют лозунги, притворяются людьми, публикуют статьи, продают дорогостоящие логотипы государству и вместе с докторами ищут способ излечить рак. Это крайне перспективное направление, которое одинаково полезно как в коммерческой деятельности, так и в повседневной жизни.
В дальнейшем влияние нейросетей на интернет будет только усиливаться, поэтому рекламистам уже приходится адаптироваться и менять стратегии работы. Нейросети затронут жизнь всех без исключения.
Как создать нейросеть: шаги и инструменты
Как начать использовать нейросети: шаг за шагом
- Определение задачи;это может быть решение задачи классификации, кластеризации, прогнозирования или любой другой задачи, для которой нейросеть может быть применена.
- Сбор данных;необходимо подготовить данные, на которых нейросеть будет обучаться. В зависимости от задачи, эти данные могут быть предоставлены, например, в виде таблицы или изображений.
- Подготовка данных;обработать и подготовить данные для обучения нейросети. Это может включать в себя удаление ненужных данных, заполнение пропущенных значений и масштабирование.
- Выбор архитектуры нейросети;архитектура определяет структуру нейросети и влияет на ее производительность. Существует множество различных типов нейросетей, включая сверточные нейронные сети, рекуррентные нейронные сети, глубокие нейронные сети и многие другие.
- Обучение нейросети;заключается в настройке весов нейронов в соответствии с предоставленными данными. Этот процесс может занять много времени и ресурсов, в зависимости от размера нейросети и объема данных.
- Оценка производительности;это может включать в себя оценку точности и скорости работы
Перед тем, как начать использовать нейросети, вам необходимо изучить основы.
В интернете есть много ресурсов, которые помогут вам понять, как работают нейросети, какие задачи они решают и как их обучают. Это можно сделать на бесплатных онлайн-курсах по машинному обучению от Google и Microsoft;
Если английский язык не знаете, открывайте страницу в Яндекс Браузере и нейросеть от Яндекса переведет вам на русский язык не только текст, но и видео.
- Общие сведения об обработке и анализе данных для машинного обучения – Training | Microsoft Lea
- Understand the basics of machine learning – Google Digital Unlocked (learndigital.withgoogle.com)
Далее выбираете фреймворк для работы с нейросетями. На рынке существует множество фреймворков для машинного обучения и нейронных сетей. Некоторые из наиболее популярных фреймворков:
- TensorFlow от Google;
- PyTorch от Facebook;
- Keras, которая является надстройкой над TensorFlow;
- Caffe от Berkeley Vision и др.

Каждый фреймворк имеет свои преимущества и недостатки. Выберите тот, который лучше всего соответствует вашим потребностям.
Для обучения нейросетей необходимо иметь данные.
Можно использовать открытые наборы данных, которые доступны в интернете, или создать свой собственный набор данных. Некоторые популярные открытые наборы данных:
- MNIST для распознавания рукописных цифр;
- CIFAR-10 для классификации изображений;
- ImageNet для классификации изображений.
Далее нужно эти данные подготовить:
- Преобразовать данных в формат, который можно использовать для обучения нейросетей;
- Провести нормализацию данных;
- Разделение данных на обучающую и тестовую выборки.
Создание и обучение модели.

Тестирование и улучшение модели.
Тестировать ее нужно на разных наборах данных для улучшения результатов.
Для тестирования модели используют отдельный набор данных, который не был включен при обучении модели. Это поможет избежать переобучения и оценить реальную производительность модели на новых данных.


После тестирования модели можно провести анализ результатов и улучшить ее производительность. Один из способов – изменить параметры модели, например, число скрытых слоев и нейронов в каждом слое. Также можно изменить архитектуру модели, выбрав другой тип слоев или комбинацию слоев.
Еще один способ – взять более продвинутые алгоритмы оптимизации, такие как Adam, RMSprop или SGD с импульсом, чтобы ускорить обучение и улучшить результаты.
Чтобы использовать модель, вам нужно загрузить ее в ваше приложение или программу.
Это написание кода для загрузки модели и обработки данных, или использование библиотеки или фреймворк, который облегчает процесс использования модели.

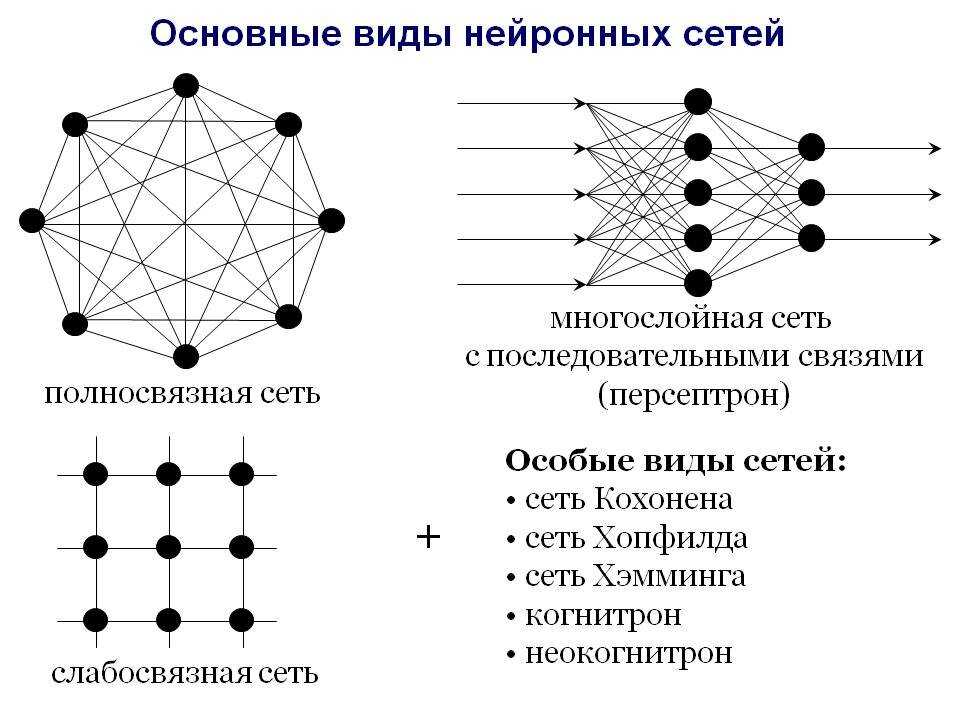
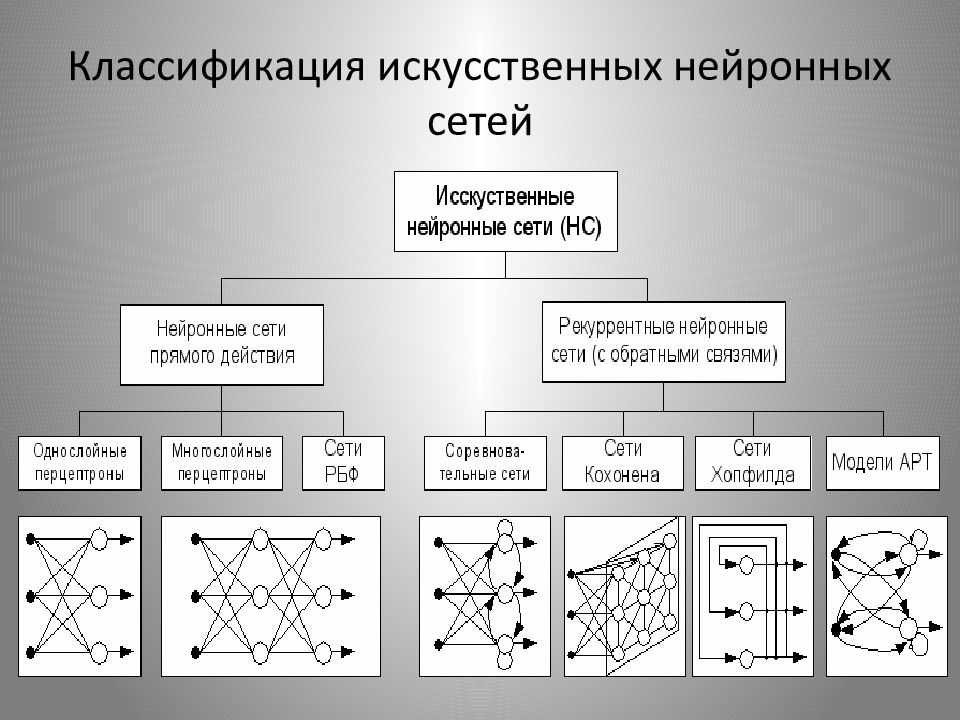
Что такое нейронные сети и их типы?
Первый вопрос, который возникает у интересующихся, что же такое нейронная сеть? В классическом определении это определённая последовательность нейронов, которые объединены между собой синапсами. Нейронные сети являются упрощённой моделью биологических аналогов.
Программа, имеющая структуру нейронной сети, даёт возможность машине анализировать входные данные и запоминать результат, полученный из определённых исходников. В последующем подобный подход позволяет извлечь из памяти результат, соответствующий текущему набору данных, если он уже имелся в опыте циклов сети.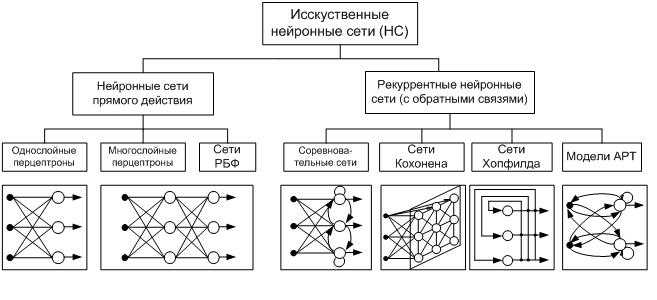
Многие воспринимают нейронную сеть, как аналог человеческого мозга. С одной стороны, можно считать это суждение близким к истине, но, с другой стороны, человеческий мозг слишком сложный механизм, чтобы была возможность воссоздать его с помощью машины хотя бы на долю процента. Нейронная сеть — это в первую очередь программа, основанная на принципе действия головного мозга, но никак не его аналог.
Нейронная сеть представляет собой связку нейронов, каждый из которых получает информацию, обрабатывает её и передаёт другому нейрону. Каждый нейрон обрабатывает сигнал совершенно одинаково.
Как тогда получается различный результат? Все дело в синапсах, которые соединяют нейроны друг с другом. Один нейрон может иметь огромное количество синапсов, усиливающих или ослабляющих сигнал, при этом они имеют особенность изменять свои характеристики с течением времени.
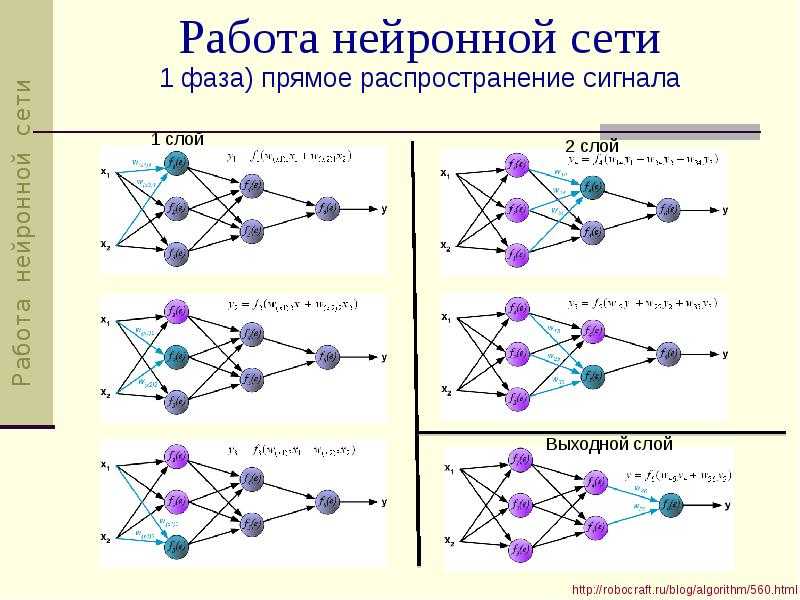
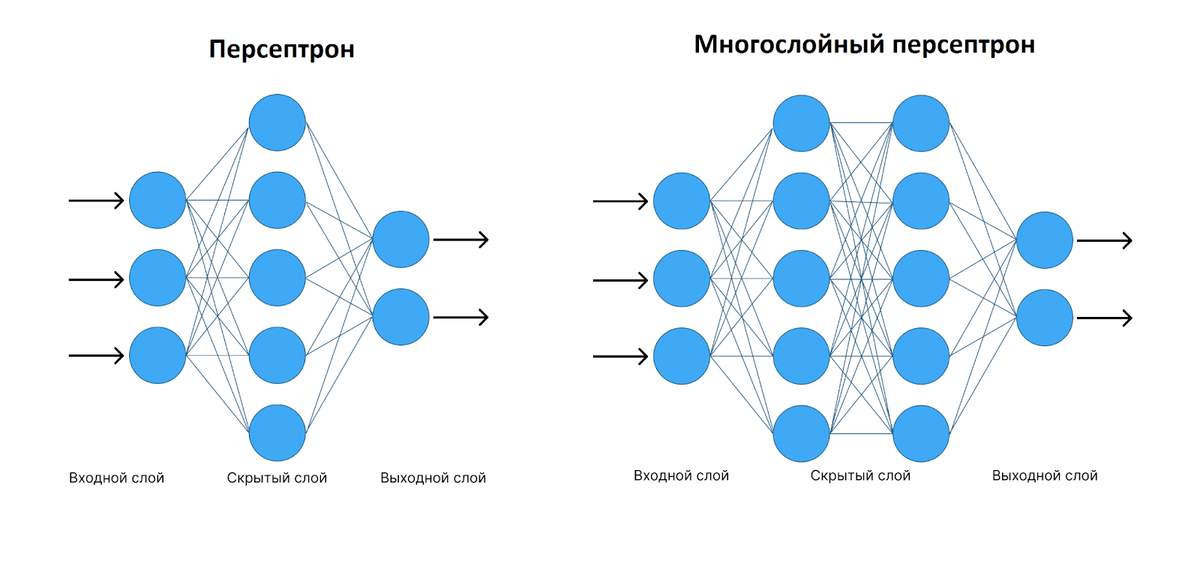
Определившись в общих чертах, что собой представляет нейронная сеть, можно выделить основные типы их классификации. Прежде чем приступить к классификации необходимо ввести одно уточнение. Каждая сеть имеет первый слой нейронов, который называется входным.
Он не выполняет никаких вычислений и преобразований, его задача состоит только в одном: принять и распределить по остальным нейронам входные сигналы. Это единственный слой, который является общим для всех типов нейронных сетей, дальнейшая их структура и является критерием для основного деления.
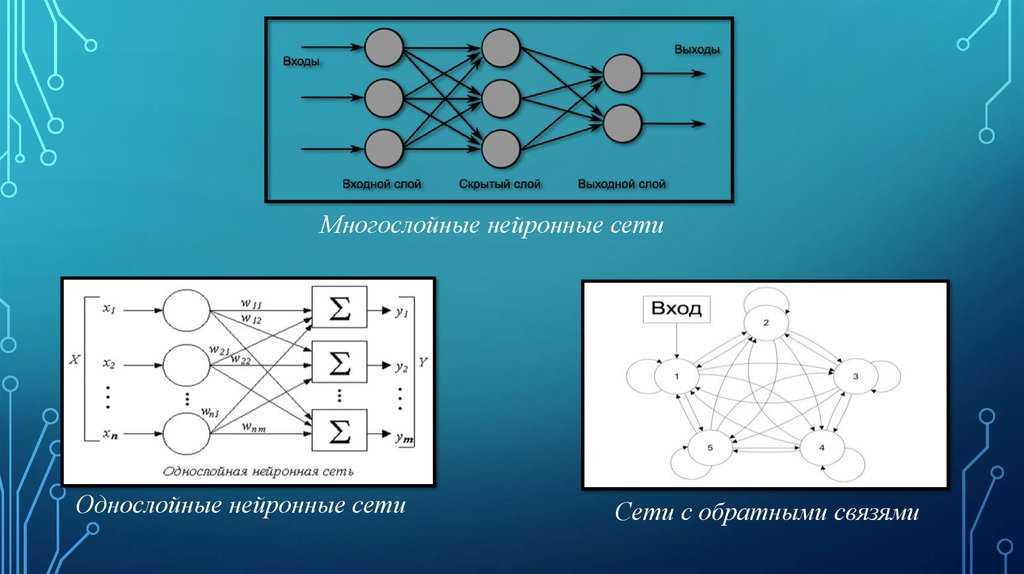
- Однослойная нейронная сеть. Это структура взаимодействия нейронов, при которой после попадания входных данных в первый входной слой сразу передаётся в слой выхода конечного результата. При этом первый входной слой не считается, так как он не выполняет никаких действий, кроме приёма и распределения, об этом уже было сказано выше. А второй слой производит все нужные вычисления и обработки и сразу выдаёт конечный результат. Входные нейроны объединены с основным слоем синапсами, имеющими различный весовой коэффициент, обеспечивающий качество связей.
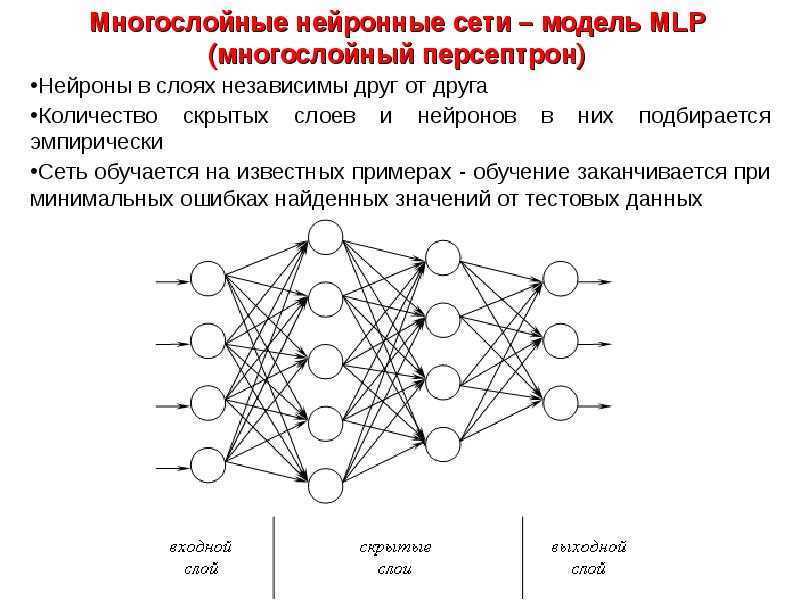
- Многослойная нейронная сеть. Как понятно из определения, этот вид нейронных сетей помимо входного и выходного слоёв имеет ещё и промежуточные слои. Их количество зависит от степени сложности самой сети. Она в большей степени напоминает структуру биологической нейронной сети. Такие виды сетей были разработаны совсем недавно, до этого все процессы были реализованы с помощью однослойных сетей. Соответственно подобное решение имеет намного больше возможностей, чем её предок. В процессе обработки информации каждый промежуточный слой представляет собой промежуточный этап обработки и распределения информации.
В зависимости от направления распределения информации по синапсам от одного нейрона к другому, можно также классифицировать сети на две категории.
- Сети прямого распространения или однонаправленная, то есть структура, в которой сигнал движется строго от входного слоя к выходному. Движение сигнала в обратном направлении невозможно. Подобные разработки достаточно широко распространены и в настоящий момент с успехом решают такие задачи, как распознавание, прогнозы или кластеризация.
- Сети с обратными связями или рекуррентная. Подобные сети позволяют сигналу двигаться не только в прямом, но и в обратном направлении. Что это даёт? В таких сетях результат выхода может возвращаться на вход исходя из этого, выход нейрона определяется весами и сигналами входа, и дополняется предыдущими выходами, которые снова вернулись на вход. Таким сетям свойственна функция кратковременной памяти, на основании которой сигналы восстанавливаются и дополняются в процессе обработки.
Это не единственные варианты классификации сетей.